
Becoming a 1.5X YAML engineer
How to use VScode plugins combined with JSON schemas to build your own YAML validators.

As an engineer, you will work a LOT with yaml files. Whether it is configuring infrastructure through kubernetes, configuring data models through dbt or configuring CI/CD with github actions. Many frameworks which use yaml for configuration have their own formatters and validators to figure out if your yaml specification is correct, but what if you need more custom behavior? If you’re working with VSCode, there is a simple way to create custom yaml validators through the use of the YAML plugin by Redhat combined with JSON schemas.
JSON schemas can represent YAML schemas
The first thing to highlight is that, at least since the 2009 specification of yaml 1.2 , yaml is a strict superset of JSON. What does this mean in practise? This means that proper implementation of the YAML 1.2 protocol will yield a parser that can parse both JSON and YAML. In other words, YAML can represent anything that can be represented in JSON but more. Conversely, this means we can use JSON tools to represent a subset of YAML specifications.
For the validation of JSON files, the JSON schema specification allows to express expected schemas for a JSON file through another JSON file in JSON schema format. We can use this specification to define the schema for a json file representation of a yaml file. Consider the following example yaml file:
app:
name: MyApp
version: 1.0.0
debug: true
database:
host: localhost
port: 5432
username: user
password: pass
features:
- authentication
- logging
- analytics
The JSON equivalent of this file would look something like:
{
"app": {
"name": "MyApp",
"version": "1.0.0",
"debug": true,
"database": {
"host": "localhost",
"port": 5432,
"username": "user",
"password": "pass"
},
"features": [
"authentication",
"logging",
"analytics"
]
}
}
The json schema that would represent the above schema looks as follows in json-schema format:
{
"$schema": "<http://json-schema.org/draft-07/schema#>",
"type": "object",
"properties": {
"app": {
"type": "object",
"properties": {
"name": {
"type": "string"
},
"version": {
"type": "string",
"pattern": "^[0-9]+\\\\.[0-9]+\\\\.[0-9]+$"
},
"debug": {
"type": "boolean"
},
"database": {
"type": "object",
"properties": {
"host": {
"type": "string"
},
"port": {
"type": "integer",
"minimum": 1,
"maximum": 65535
},
"username": {
"type": "string"
},
"password": {
"type": "string"
}
},
"required": ["host", "port", "username", "password"]
},
"features": {
"type": "array",
"items": {
"type": "string"
}
}
},
"required": ["name", "version", "debug", "database", "features"]
}
},
"required": ["app"]
}
As you can probably tell, the json schema defines an expected schema for a json file. The json schema specification allows for many different kinds of validation mechanisms. In the above example, you can see that it’s possible to indicate which keys an object should at least have through required . You can also see that we can define validations for specific fields such as a minimum and maximum port number and a regular expression pattern for version.
Considering the above, we can use json schemas to represent validation rules for yaml files, but how can we easily integrate this in our interactive development environment? If you are using VScode, the YAML extension by RedHat offers a very simple solution.
Custom YAML validation with JSON schemas in VScode
The first step is to install the YAML extension redhat.vscode-yaml in VScode
Now, in your settings.json file for VScode, you can create a map between json schema and yaml files to validate with that json schema. So for example:
"yaml.schemas": {
"<absolute path to schema>": [
"/**/*app.y*ml",
]
}
The above will tell us that the json schema custom_app_yaml_schema.json will be used to validate any YAML file on our system that ends with app.yaml or app.yml (though technically the regex would pick up something like app.ybml too but that’s besides the point).
Now, let’s take the above json schema and use it with the app.yml we’ve described before.
Now to make potential validation errors more obvious when I open the yaml file, I add another extension called usernamehw.errorlens which adds a more obvious highlight for errors:
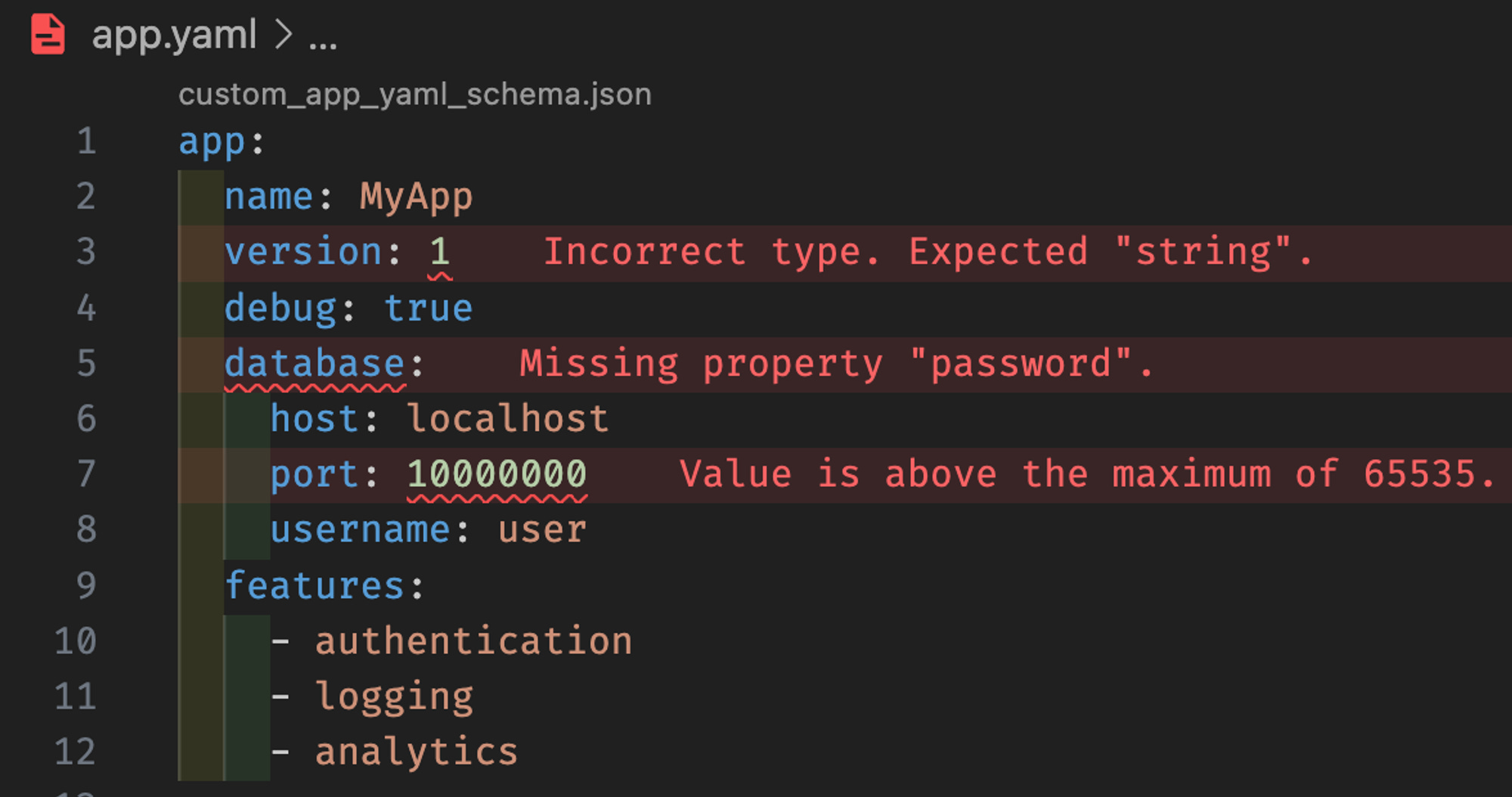
Now, let’s say we purposefully create some alterations of this yaml file that don’t fit the schema. We now get real time feedback from the JSON schema on our invalid configuration!
Pretty cool hu?
This can be a very powerful tool in your IDE. In the rest of this article we will go a little bit more in depth into json schemas and how we can work with them to configure various kinds of validations.
JSON schema customizations
JSON schemas can have a bit of a learning curve when it comes to writing correct expressions. There have also been quite a few releases over the years when it comes to specifications. Please keep in mind what schema your tooling supports. As of today, the YAML extension support schemas of format draft 7, so I will keep to functionality specific to that draft.
json-schema documentation is pretty all encompassing when it comes to capabilities. In this section I want to highlight a few parts of the specification that have been useful for me so far:
The root elements
Each json schema document will have a few minimum root elements:
title: The title of the document$schema: A url to the json schema specification.
The $schema element here points to any of the official json draft specifications. We have actually seen one in the example schema before: https://json-schema.org/draft-07/schema. Go ahead, click that link. You will notice that the schema is defined in a json-schema like format!
Json schema types
The basic non-hierarchical data types are string, integer, number, boolean and null. These are types that cannot have nested or recursive interpretations. For those use cases, there’s arrays (equivalent to a python list or tuple) and objects (equivalent to a python dictionary). Let’s go into a little more detail of each.
Null and boolean
The simplest of these are null and boolean which have straightforward meanings for each programming language interface provided to json schema. For example, null will evaluate to None in python.
Numeric types
Integers and numbers have more validation available to them. It’s possible to define a number must be a multipleOf a certain factor. The example below will only accept multiples of ten:
{
"type": "number",
"multipleOf" : 10
}Ranges of numbers are specified using a combination of the minimum and maximum keywords, (or exclusiveMinimum and exclusiveMaximum for expressing exclusive range).
If x is the value being validated, the following must hold true:
x ≥ minimum
x > exclusiveMinimum
x ≤ maximum
x < exclusiveMaximum
While you can specify both of minimum and exclusiveMinimum or both of maximum and exclusiveMaximum, it doesn't really make sense to do so.
The following example will allow values 0 through 99:
{
"type": "number",
"minimum": 0,
"exclusiveMaximum": 100
}String types
String types are the most flexible type. Strings have a variety of validation tools to their disposal.
The simplest validation tool is length .
The length of a string can be constrained using the minLength and maxLength keywords. For both keywords, the value must be a non-negative number.
The following defines that a string must be between 2 and 3 characters long:
{
"type": "string",
"minLength": 2,
"maxLength": 3
}Format can be used to define that a string has a certain format like an e-mail address. Do note that support for various formats depends on the implementation of the json schema at hand. The “canonical” supported formats as per specification can be found here.
For example, if we have an e-mail, we may define it as:
{
"type": "string",
"format": "email",
}Finally, for the most flexibility we can user regular expressions through the pattern keyword. Keep in mind that json schema maintains a specific implementation of regular expressions which can be viewed here.
For example, if we want to define a string should start with { and end with } it can be defined as follows:
{
"type": "string",
"pattern": "^\\\\{\\\\{(.|[\\\\r\\\\n])*\\\\}\\\\}$",
}
Array
Arrays are the first type that we discuss that define more than one element.
There are two ways in which arrays are generally used in JSON:
List validation: a sequence of arbitrary length where each item matches the same schema.
Tuple validation: a sequence of fixed length where each item may have a different schema. In this usage, the index (or location) of each item is meaningful as to how the value is interpreted. (This usage is often given a whole separate type in some programming languages, such as Python's
tuple).
There’s a few keywords that are important to understand for arrays.
Validating the type of all array elements with items and contains
Items can be used to define what the type of the elements in the list should be. For example, if we only want numbers in a list we can define that as:
{
"type": "array",
"items": {
"type": "number"
}
}If we want at least one element to be a number instead, we can use contains to define that schema:
{
"type": "array",
"contains": {
"type": "number"
}
}Tuple validation using PrefixItems
For tuple validation, we can use the keyword PrefixItems to determine the required schema of the tuple elements. Let’s say we have a tuple that defines an element street name and street type . For street name we just want to have a string. For street type we want to use a string from a specific set of strings. We can accomplish the latter through the enum keyword. This results into the following schema component:
{
"type": "array",
"prefixItems": [
{ "type": "string" },
{ "enum": ["Street", "Avenue", "Boulevard"] },
]
}We can use the items keyword as mentioned in the previous section to define more specific constraints for elements. For example, Setting items to false disallows extra elements to be added in this list:
{
"type": "array",
"prefixItems": [
{ "enum": ["Street", "Avenue", "Boulevard"] },
{ "enum": ["NW", "NE", "SW", "SE"] }
],
"items": false
}Crucially, items accepts subschemas as well and with that, arrays are the first type we described in this article that can act as a “container” for other types:
{
"type": "array",
"prefixItems": [
{ "enum": ["Street", "Avenue", "Boulevard"] },
{ "enum": ["NW", "NE", "SW", "SE"] }
],
"items": { "type": "string" }
}There are more keywords that can be used with arrays but for the sake of brevity we won’t go over those here.
Objects
Objects are the mapping type in JSON. They map "keys" to "values". In JSON, the "keys" must always be strings. Each of these pairs is conventionally referred to as a "property".
The properties (key-value pairs) on an object are defined using the properties keyword. The value of properties is an object, where each key is the name of a property and each value is a schema used to validate that property. Any property that doesn't match any of the property names in the properties keyword is ignored by this keyword.
Let’s take the same example as the tuple validation example specified in the array section. We have a street_name and a street_type . In an object, we can define this as follows:
{
"type": "object",
"properties": {
"street_name": { "type": "string" },
"street_type": { "enum": ["Street", "Avenue", "Boulevard"] }
}
}Objects have different keywords that encompass similar behavior to those found in arrays , however, One thing that objects are particularly well suited for is creating more complex schema compositions. We will go into more complex schema generation into the following sections because there is some context to be understood before diving into that.
Structuring a Complex Schema in JSON Schema: The URI model
When working with JSON Schema, it's advantageous to structure your schemas into reusable components, much like how you would structure your code with functions and modules. This approach not only promotes reusability but also makes your schemas easier to maintain and extend.
Schema Identification
Schemas are identified using non-relative URIs, which act as unique identifiers. Although schemas are not required to have an identifier, having one allows you to reference them from other schemas. In this context, schemas without identifiers are termed "anonymous schemas."
Base URI and $id
The base URI of a schema is crucial for resolving relative references. By default, the base URI is the retrieval URI of the schema. You can explicitly set the base URI using the $id keyword. For example:
{
"$id": "<https://example.com/schemas/address>",
"type": "object",
"properties": {
"street_address": { "type": "string" },
"city": { "type": "string" },
"state": { "type": "string" }
},
"required": ["street_address", "city", "state"]
}In this schema, $id sets the base URI to https://example.com/schemas/address. Please do note that this does NOT neccecarily mean it is fetched from this webaddress.
Even though schemas are identified by URIs, those identifiers are not necessarily network-addressable. They are just identifiers. Generally, implementations don't make HTTP requests (https://) or read from the file system (file://) to fetch schemas. Instead, they provide a way to load schemas into an internal schema database. When a schema is referenced by it's URI identifier, the schema is retrieved from the internal schema database.
The URI https://example.com/schemas/address#/properties/street_address identifies the street_address property in the schema.
$ref for Reusing Schemas
The $ref keyword allows you to reuse existing schemas.
Example:
{
"$id": "<https://example.com/schemas/customer>",
"type": "object",
"properties": {
"first_name": { "type": "string" },
"last_name": { "type": "string" },
"shipping_address": { "$ref": "<https://example.com/schemas/address>" },
"billing_address": { "$ref": "<https://example.com/schemas/address>" }
},
"required": ["first_name", "last_name", "shipping_address", "billing_address"]
}Here, both shipping_address and billing_address reference the same address schema, ensuring consistency and reducing redundancy.
$defs for Local Subschemas
Use $defs to define subschemas that are intended for reuse within the same schema document. This keeps your schema organized and readable.
Example:
{
"$id": "<https://example.com/schemas/customer>",
"type": "object",
"properties": {
"first_name": { "$ref": "#/$defs/name" },
"last_name": { "$ref": "#/$defs/name" },
"shipping_address": { "$ref": "<https://example.com/schemas/address>" },
"billing_address": { "$ref": "<https://example.com/schemas/address>" }
},
"required": ["first_name", "last_name", "shipping_address", "billing_address"],
"$defs": {
"name": { "type": "string" }
}
}Recursive Schemas
Schemas can be recursive, referring to themselves, which is useful for representing hierarchical structures like trees.
Example:
{
"type": "object",
"properties": {
"name": { "type": "string" },
"children": {
"type": "array",
"items": { "$ref": "#" }
}
}
}This schema defines a recursive structure where each children array can contain items that follow the same schema.
Bundling Schemas
For distribution, you might want to bundle multiple schemas into a single document. This can be done using $id in subschemas, creating a compound schema document.
Example:
{
"$id": "<https://example.com/schemas/customer>",
"$schema": "<https://json-schema.org/draft/2020-12/schema>",
"type": "object",
"properties": {
"first_name": { "type": "string" },
"last_name": { "type": "string" },
"shipping_address": { "$ref": "#/$defs/address" },
"billing_address": { "$ref": "#/$defs/address" }
},
"required": ["first_name", "last_name", "shipping_address", "billing_address"],
"$defs": {
"address": {
"$id": "<https://example.com/schemas/address>",
"type": "object",
"properties": {
"street_address": { "type": "string" },
"city": { "type": "string" },
"state": { "$ref": "#/definitions/state" }
},
"required": ["street_address", "city", "state"],
"definitions": {
"state": { "enum": ["CA", "NY", "... etc ..."] }
}
}
}
}
Bundling schemas this way ensures all necessary components are included in a single document, making it easier to share and maintain.
Applying binary operators on schemas
The keywords used to combine schemas are:
allOf: (AND) Must be valid against all of the subschemasanyOf: (OR) Must be valid against any of the subschemasoneOf: (XOR) Must be valid against exactly one of the subschemas
All of these keywords must be set to an array, where each item is a schema. Be careful with recursive schemas as they can exponentially increase processing times.
In addition, there is:
not: (NOT) Must not be valid against the given schema
This can be used as follows for example:
{
"allOf": [
{ "type": "string" },
{ "maxLength": 5 }
]
}Wrapping up
This article went into depth on how custom validators can be configured for any set of YAML files with custom json schemas and the yaml extension on VScode. We went in depth into how JSON schemas can be constructed to validate various types of documents. In a next article, we will focus on applying this to a specific use case for data (analytics) engineering for maintaining YAML state of dbt yaml files by showing how we can interface with these validations through python as well.