
Building custom DBT applications with DBT runner
Leveraging the DBT graph for governance

Introduction
Why building in house governance solutions makes sense
Many data teams have been leveraging vast troves of data on modern data warehouse platforms like snowflake and databricks. For a lot of these data teams, adopting data build tool (dbt) as their main data transformation management tool was a bliss, especially at smaller project sizes. However, complexity is rising quickly, just observe the growth of dbt project sizes over time:
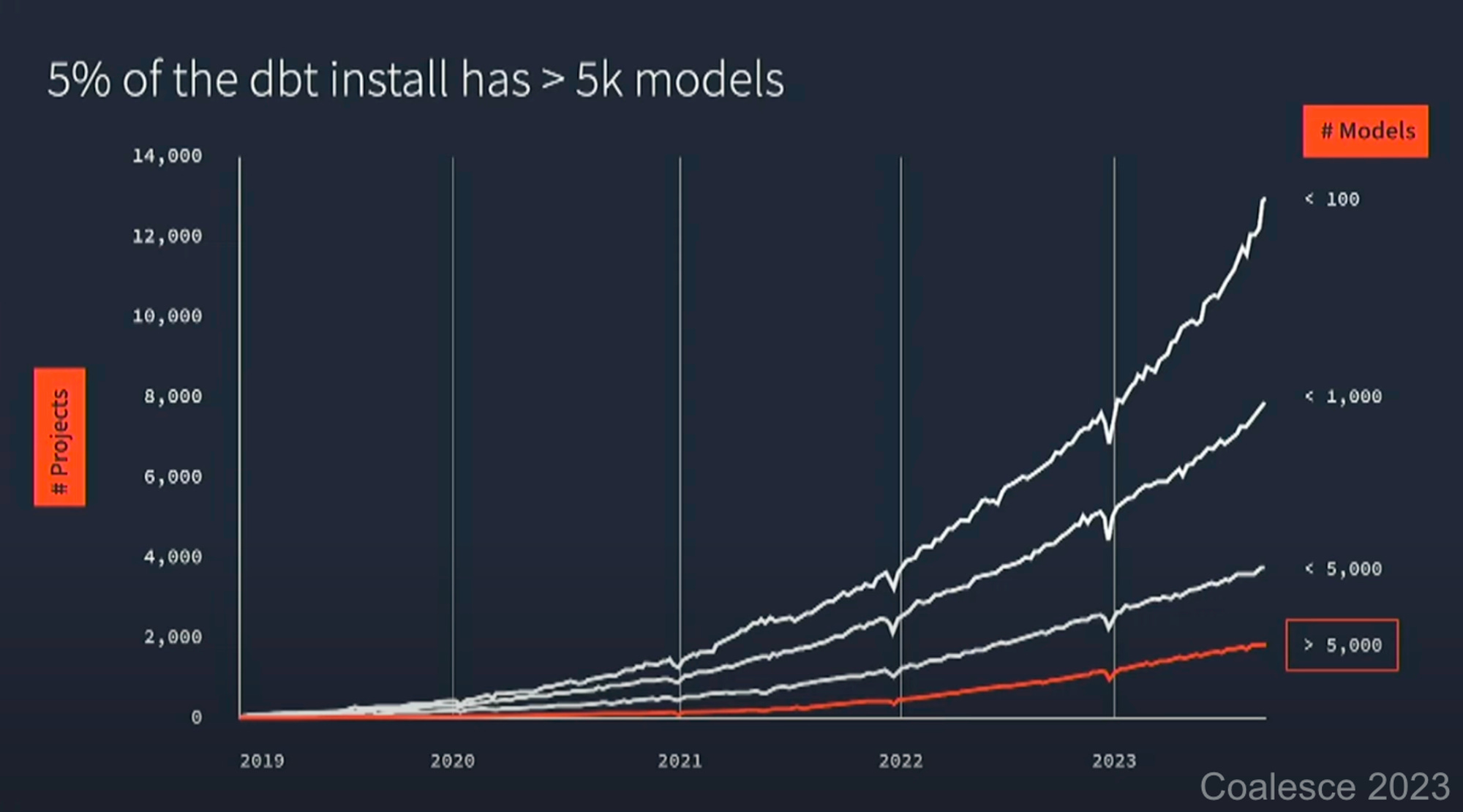
This explosive growth of data has turbocharged the need for data observability and governance.
When it comes to data governance, there are a lot of different goals that companies may want to pursue:
For some companies, proper data protection/data masking is key when subject to GDPR in Europe or HIPPAA/HITECH with medical data in the US.
For other companies, getting a grip on their spiraling data warehouse costs may be a key priority
Yet other may have a lot of external facing data products that need to have high availability and low error rates in real time
However, addressing these needs with external tooling is challenging.
Data quality is a vastly different problems to other areas that see more succesful SaaS and PaaS solutions. For example, ETL connectors provided by companies such as FiveTran and Portable solve a well defined problem of ingesting data from one place and deposing it in another. This is a problem that impacts many companies in similar ways, but the problem space for data quality and observability is much more vast and much more dependent on the internals of the company and industry.

When it comes to data governance, there are a lot of different goals that companies may want to pursue:
For some companies, proper data protection/data masking is key when subject to GDPR in Europe or HIPPAA/HITECH with medical data in the US.
For other companies, getting a grip on their spiralling data warehouse costs may be a key priority
Yet others may have a lot of external facing data products that need to have high availability and low error rates in real time
etc…
In the current economy, we are seeing high interest rates leading to tight budgets and smaller technical team headcount to weather the storm. The last thing a company is waiting for right now is to pay top dollars for data governance platforms that are only solving SOME of their problems while paying for the rest of the platform features, many of which this specific company may not need.
We can see that adoption of tooling in this space is still very early stage:
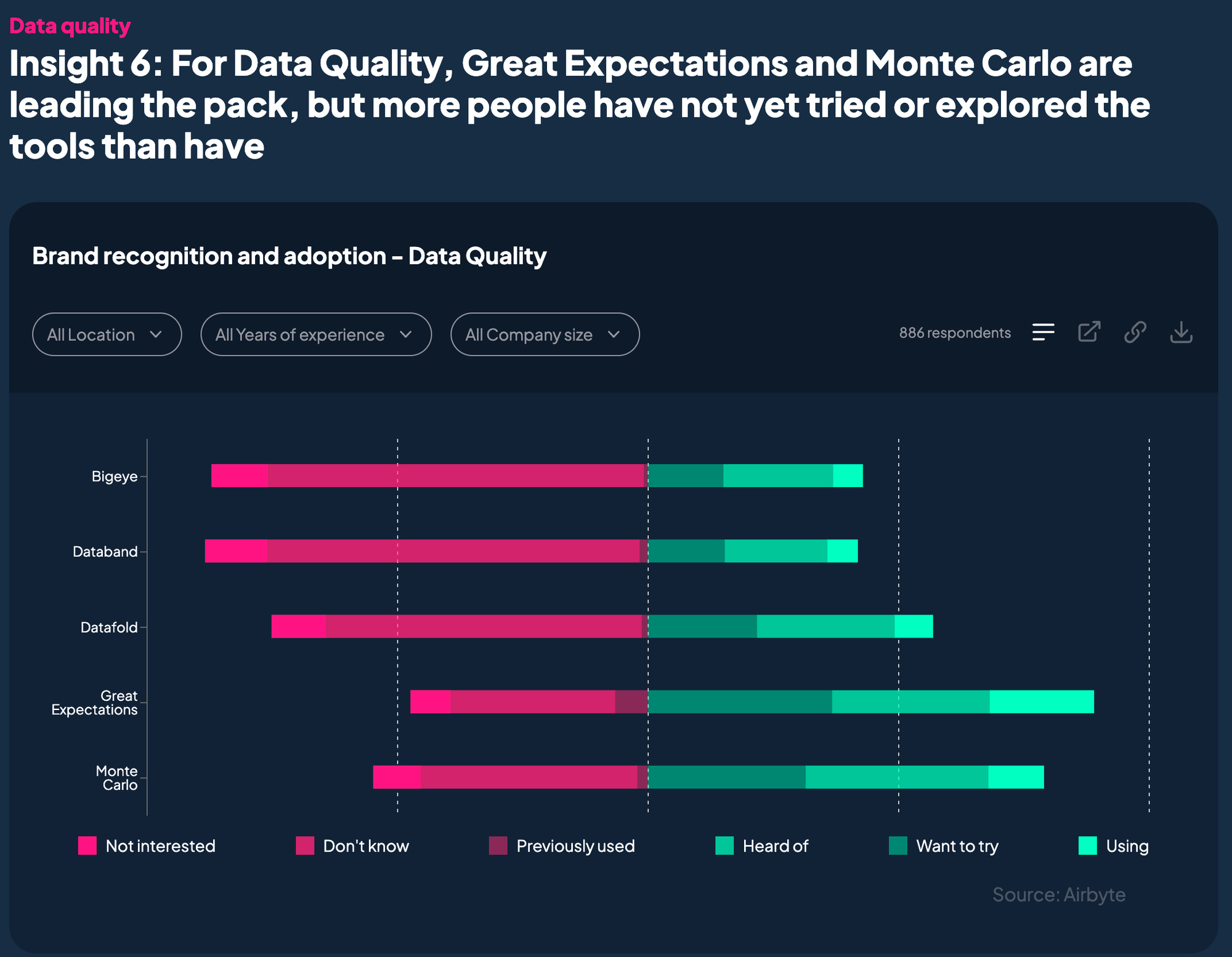
Considering these things, we are seeing the return of teams building capabilities in house. In such a market environment, it’s invaluable to be able to deliver custom solutions within the confines of the omnipotent DBT framework.
In this article series, we will delve deeper into the internal of dbt metadata and how we can leverage that to build governance capabilities for internal data platform teams.
In this article, we will focus on step 1: The input data.
What are DBT artifcats?
Whenever you run a dbt command on the CLI, a chain of events is cascaded into the dbt-core backend. One of these events is the production of so called artifcats. In simple terms, these are files containing metadata about the state of your full dbt project.
There are several different kinds of metadata files, all of which contain metadata from several different aspects of the dbt project. Many of dbt’s functions such as dbt run or dbt build and their options —select rely on this backend of data to work properly. The main artifcats produces as of today are:
manifest: produced by commands that read and understand your project
run results: produced by commands that run, compile, or catalog nodes in your DAG
catalog: produced by
docs generatesources: produced by
source freshness
Understanding what is available in these artifcats and how to work with them is crucial to building custom DBT solutions for managing your data projects.
To look more in depth into all the available fields for these manifest, please refer to the official JSON schemas provided by dbt https://schemas.getdbt.com/.
The DBT manifest and yml schemas
In this article, we will specifically focus on the manifest.json, as this is the most important and information rich file in most DBT projects.
To view the dbt manifest in your project without running any actual models, simply run:
dbt parseThis command will parse all the files in your dbt project and generate a manifest.json in a subfolder of your dbt project called target .
As of today (manifest version 11) there are the following main top level fields:
metadata
nodes
sources
macros
docs
exposures
Each of these fields will have their own sub-schema in the json schema. However, the manifest schema can sometimes be a bit tricky to read as theres a lot of available metadata fields for various objects. It’s usually easier to view some example records in the manifest.json file directly. Here’s an (simplified) example of a model node from the dbt_facebook_ads repo https://github.com/fivetran/dbt_facebook_ads/tree/main:
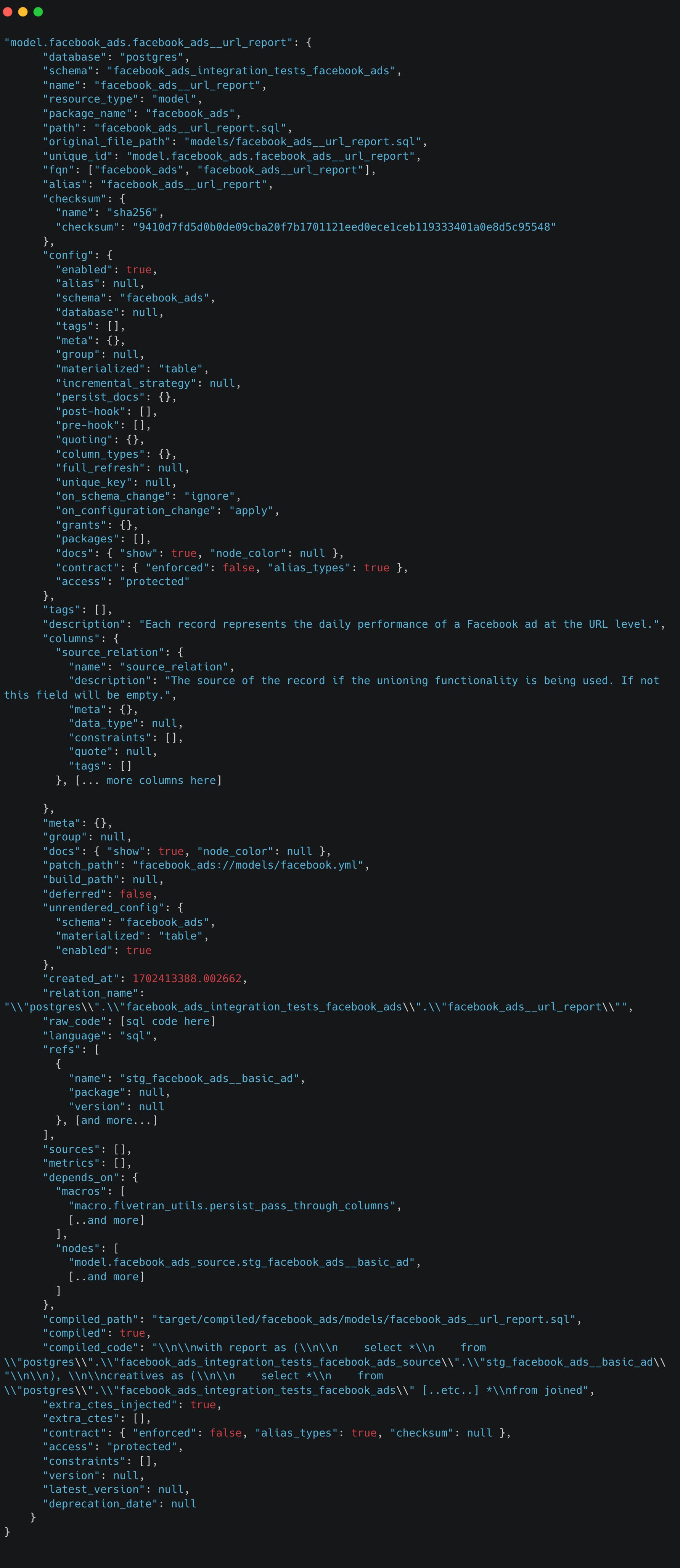
As you can tell, we have quite a bit of configuration available to us here! You can think of these fields on a higher level falling into four rough categories:
Database details of the model (what database, what schema, what was the query that was run etc…)
Configuration of the individual model. Either derived from configuration blocks in the .
sqlfiles, theproperties.ymlfile or project level settings atdbt_project.yml.Relations with other models. This can be parent/daugther relationships, contracts, and other aspects of inter-model relationships.
Relation to the dbt project. Think of path of the model file, the unique model id, etc…
We can parse these fields in several ways to do something actionable with them.
Parsing DBT manifest data
If you have a decently sized project, taking a look at the manifest.json will quickly make you realise there is a lot of data in there. To start working with this in a more structured way, let’s explore a couple of different ways in which you may tackle parsing this data.
Tackling stuff heads on by parsing the json file
The first and most obvious approach you may think of is to tackle the dbt manifest right on with common tools used for json parsing such as command line tools like jq , custom python scripts or using typical data wrangling libraries like pandas. Although it is possible to approach things this way, it is not the route I recommend as it’s rather detached from using dbt internals.
Using the graph variable in dbt macros to parse projects
Within the jinja context (nice resource here) of a dbt macro, a lot of the project data can be accessed by working with the graph context variable (see reference here). For a lot of applications, this may be the preferred approach to handling dbt project data, a couple reasons are:
Using a dbt macro allows to use the standard authentication method of your database or data warehouse.
By parsing projects in the dbt macro, it can be easier to connect parsing outcome with specific SQL commands in your database/data warehouse.
With a macro, it is easier to control the timing of your code execution. A macro may be applied during a model run, a dbt pre-hook or post-hook, or a combination of specific selection criteria (e.g only during a
dbt buildcommand).As macros are tightly integrated with how dbt operates, it is easier to integrate any project parsing macro’s with your projects CI/CD process or add them as hooks in your project.
The downside is that it can be complicated to implement non-trivial logic in jinja compared to a fully fledged language such as vanilla python. There’s only a limited set of python capabilities within this jinja context.
So, how can we use this? Simple, the graph variable contains a dictionary representation of the manifest so we can access it’s elements just like we would normally do with dictionaries in jinja.
Let’s say we want to parse our model data from the manifest, we can simply do this with:
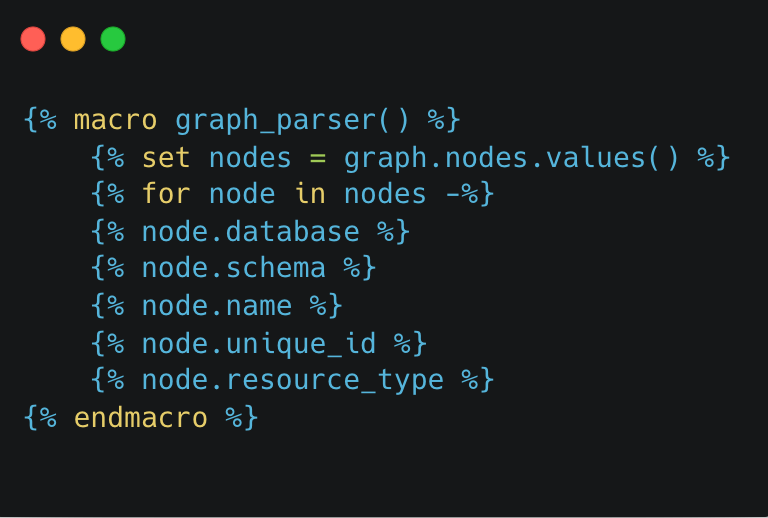
As we are accessing the same elements as we may see in a node element in the manifest.json
Now, let’s say we would want to parse some metadata tags in the columns of our models, we may do something like:
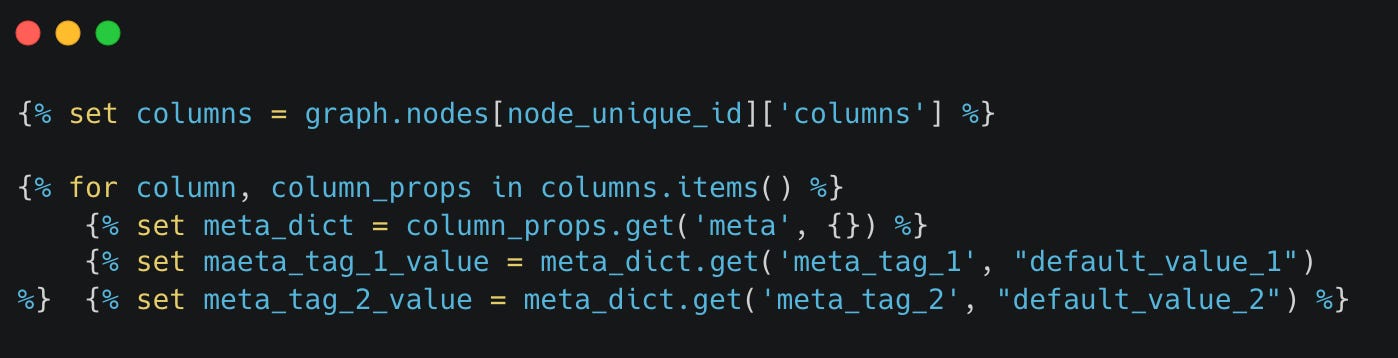
As you can see, this can be quite useful, but it is not the only way to work with the data produced in the manifest.
Using the dbtrunner to parse dbt-core objects
Since the release of dbt core v1.5, the dbtRunner class has been introduced which allows us to programmatically invoke dbt cli commands and return their internal python data classes. This can be used to parse the dbt project in the most powerful way. Some considerations with this approach:
Please read the caveats provided by dbt on the support of these endpoints. The way this works / the values it returns is subject to change in the future https://docs.getdbt.com/reference/programmatic-invocations#commitments--caveats
This approach can be powerful as the python data classes that are returned contain a lot more fields and objects compared to the dbt manifest. This can allow for the building of a wider array of applications.
This is run within standard python and as such has the most flexibility when it comes to programming logic and or the inclusion of other libraries.
Because this is using DBT commands more natively, it is able to build applications that more natively support the use of powerful dbt features such as model lineage, selectors and many many more things.
Natively picks up any configuration of your dbt project as it’s running dbt commands in the same way as a cli command would be executed.
As of today, the source code for this implementation can be found in the core library at dbt.cli.main https://github.com/dbt-labs/dbt-core/blob/9bb970e6ef26907b993d4e51de6dc6ef95fe4aa0/core/dbt/cli/main.py#L61. Let’s take a look at what we can do with this.
Generating a Manifest dataclass object
First, let’s write a simply python script which wil parse our project with dbt parse and return to us a Manifest object.
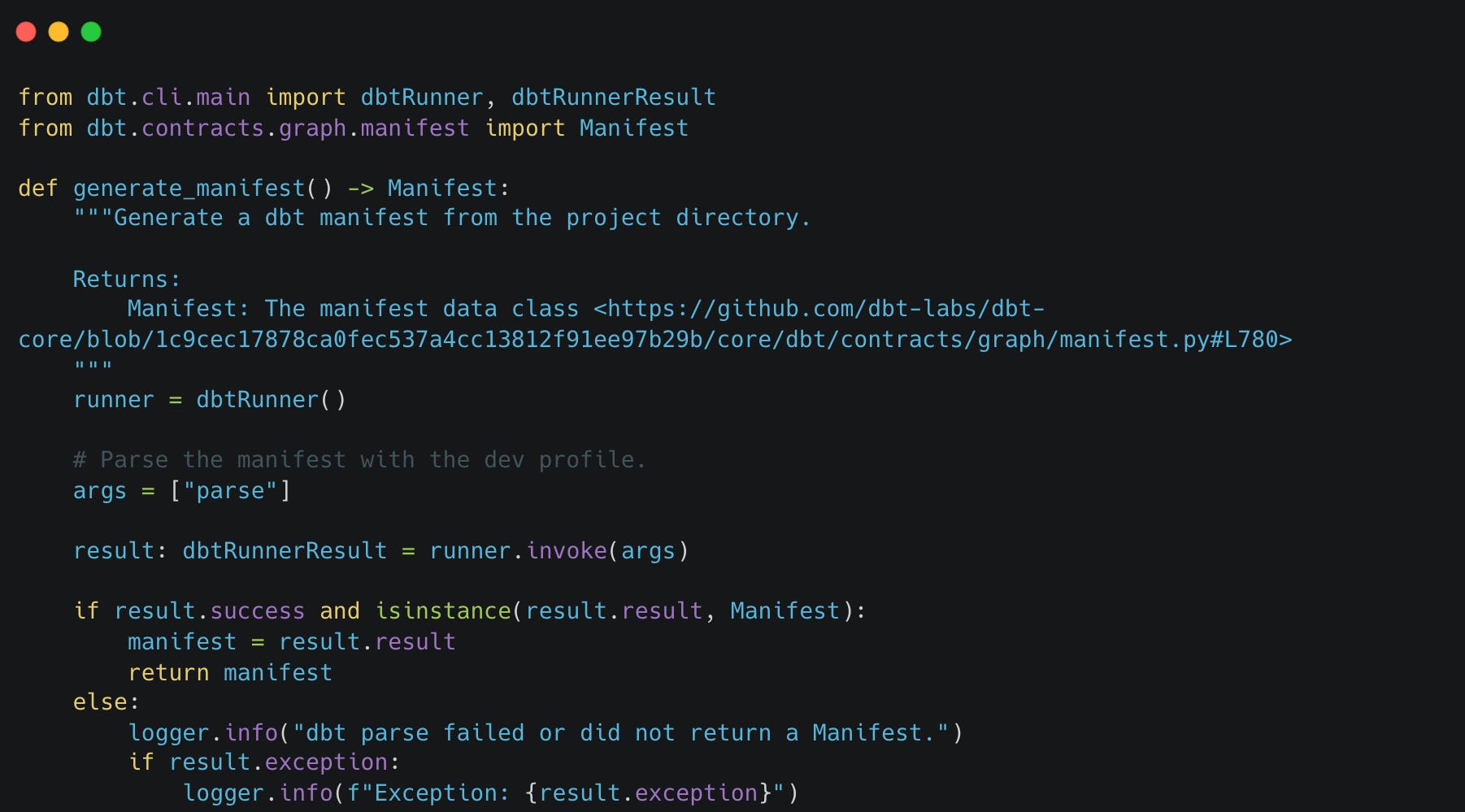
Running this python script in your project will output the same text to your terminal as when you run dbt parse. It will also yield a manifest file in a similar way at the target folder of your dbt project, but it also returns a much more powerful Manifest object. Let’s take a look at the source code for this Manifest object to understand better what it can provide to us.
Under dbt.contracts.graph.manifest.py we can find the class definition https://github.com/dbt-labs/dbt-core/blob/9bb970e6ef26907b993d4e51de6dc6ef95fe4aa0/core/dbt/contracts/graph/manifest.py#L780
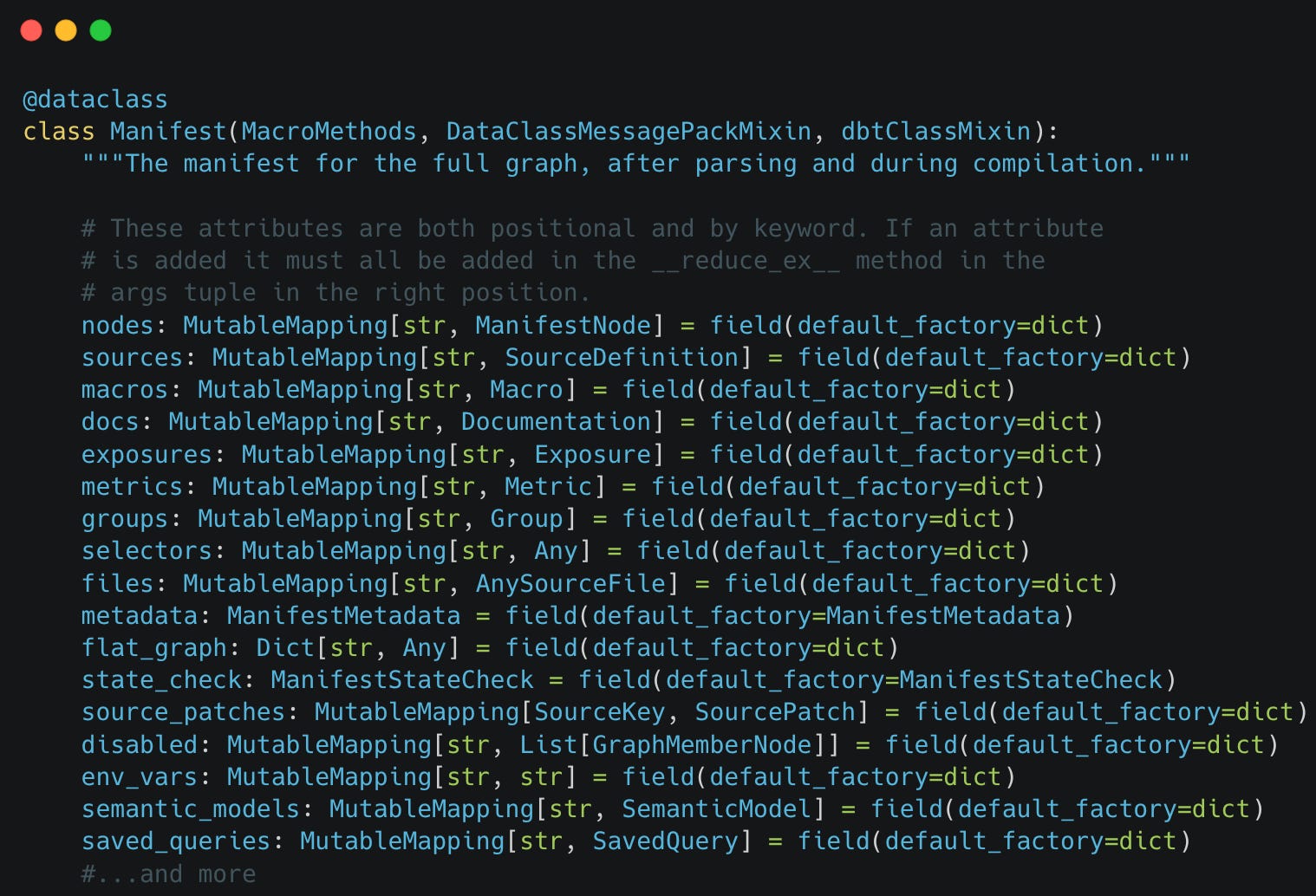
Wow! That sure is a lot of available data fields.
You will notice some familar data fields from the dbt manifest such as nodes , sources , macros etc. What you may also notice is that many of these have their own subclasses as well: Nodes are based on ManifestNode , sources are based on SourceDefinition , etc. More interestingly, there are also fields present in this data class that are never defined in the manifest.json . Take a look at files which is based on AnySourceFile . If we delve deeper into it’s implementation under dbt.contracts.files and try to print some of it’s data we can actually see a data representation of which yaml and sql files were parsed in the dbt project and the full conent of those yaml and sql files.
Parsing subsections of manifest dataclass
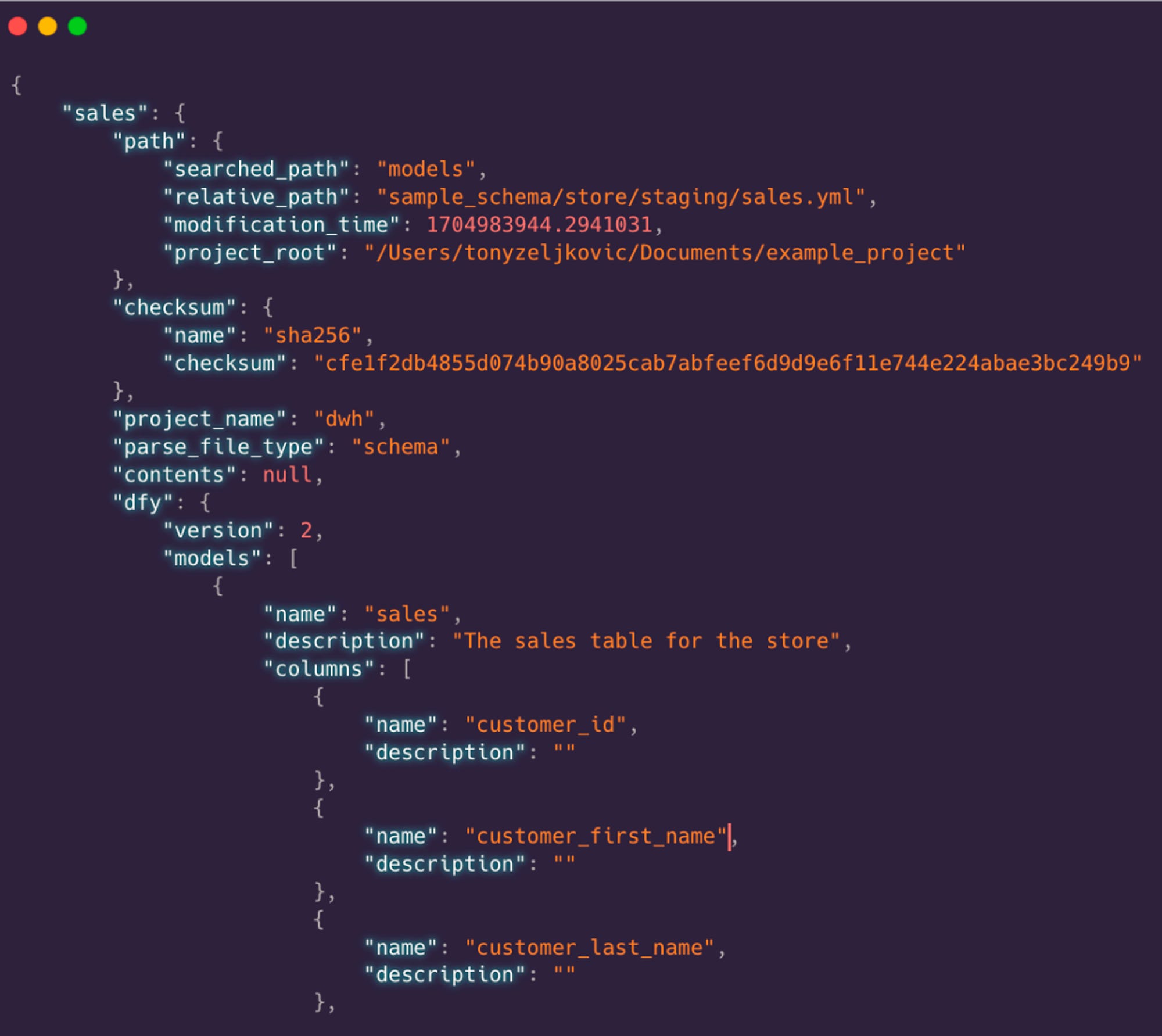
I hope you start to see some pretty powerful possibilities in here. For example, we can write some pretty simple python code to write a representation that informs us what model data can be associated with available YAML data.
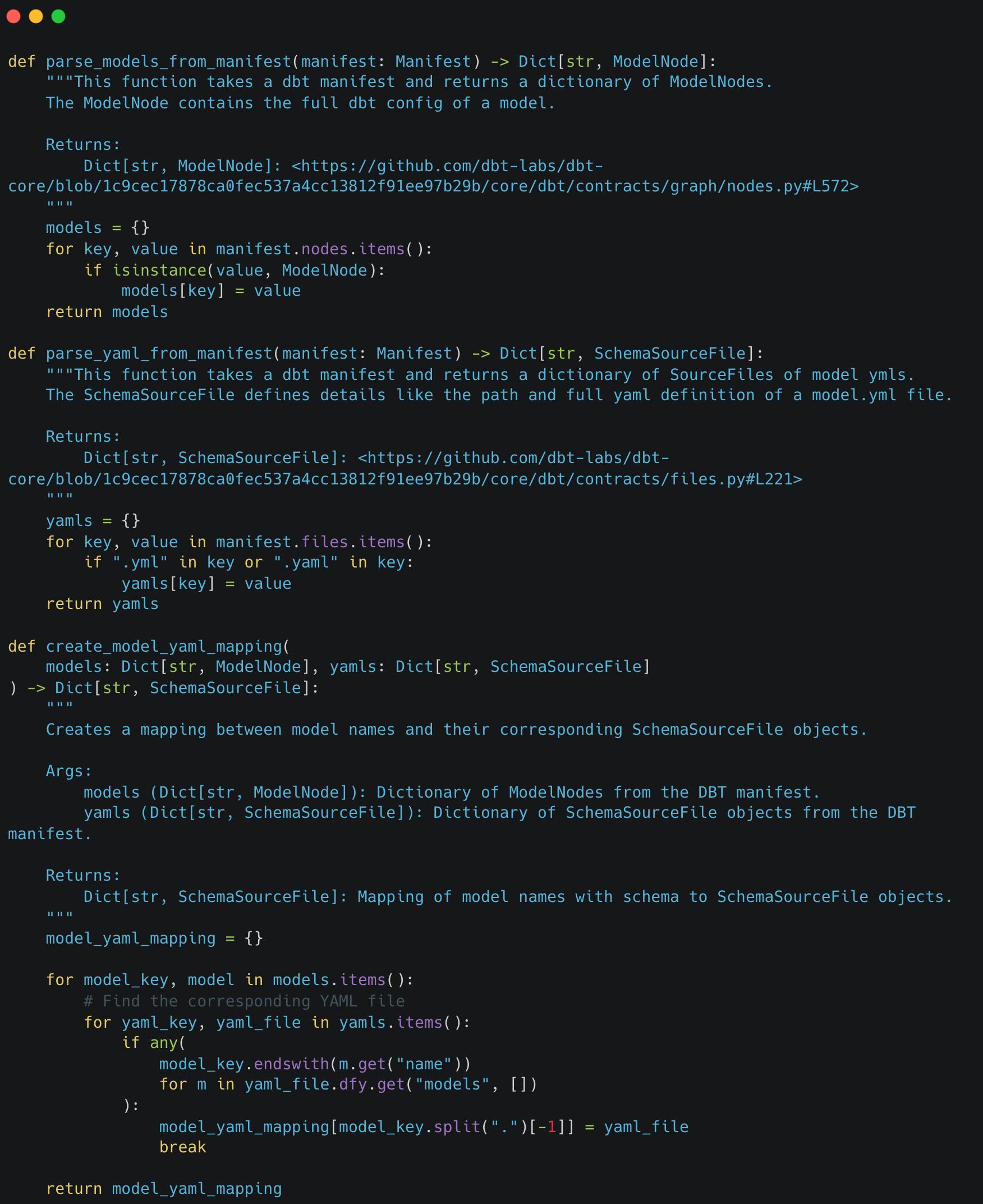
This simple transformation yields a dictionary where the key is the model name and the value is the yaml file data, including it’s full file path, it’s full definition and much more. The data will look something like below:
Final words
In this article we discussed the value of developing in house governance solutions, the power of dbt artifcats, especially the manifest and discussed various ways of parsing the manifest data for use by downstream applications. In the part, we will focus on an example application which uses this data together with pytest to validate several properties of a dbt project in bulk.