
Data Hustle #1: Finding Value in Optimizing Small Queries
How optimizing small queries in a snowflake+dbt setup can save on a large amount of costs.

Doing more with less is something that every company on the planet benefits from.
Anyone that has been working with snowflake data warehouses with dbt will at multiple points throughout the lifetime of their warehouses engage into a cost optimisation effort of some sorts.

Data warehouses and associated costs around them are one of the largest non-human costs in a data team and as such are always a prime target for gaining most from a cost cutting effort.
It can sometimes feel a bit voodoo as to what exactly is the best way to manage costs. It’s not uncommon to devolve into platitudes or even to just assume that the compute layer will handle everything for you automatically.
That’s not to say the snowflake query engine does not do some impressive heavy lifting to optimizing cost/performance ratio on many queries but that does NOT mean you don’t need to put in more effort.
In this weeks newsletter I’ll go over some of the fallacies around snowflake cost monitoring and more advanced methods I have been using with my enterprise clients to successfully cut their snowflake spend by 50% on large 6 and 7 figure budgets when they’ve hit a wall in their cost optimization efforts.

This newsletter will assume you know the basics around snowflake costs and basic warehouse management in snowflake.
❌ Fallacy 1: Tracking queries through Role Based Access Control is enough
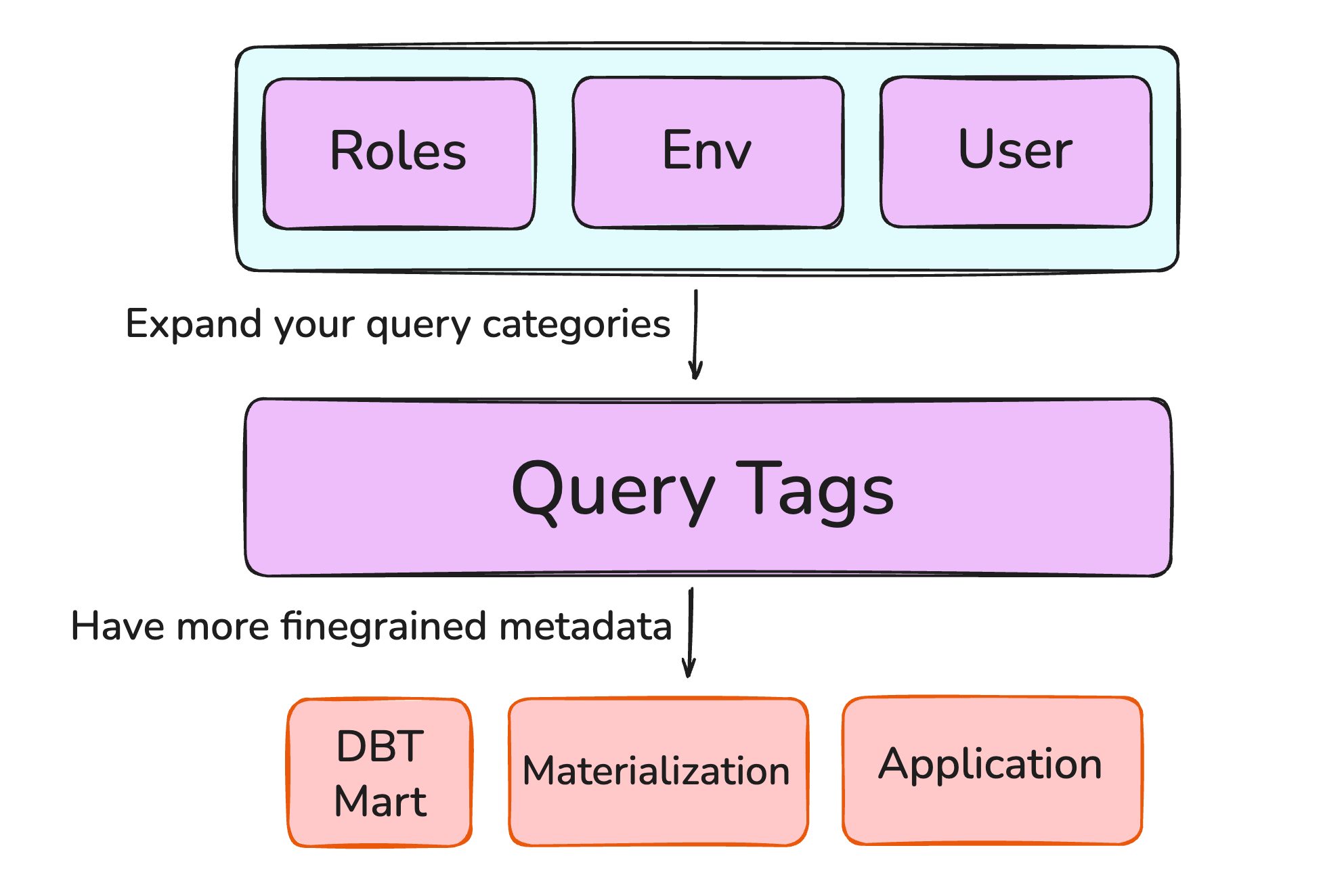
There’s many ways to divide queries into categories in your warehouse. You might split queries based on roles, based on dbt targets or even based on users. While this is a good initial approach, in order to get really detailed insights we will need to add more specific metadata because, as we will learn later, not all statements are created equally.
When deploying a data stack using snowflake, all sources, whether it be DBT, orchestrators, BI-tools or other applications will connect through some of the supported snowflake connectors.
Each connector supports the ability to add query tags, this can be a simple:
ALTER SESSION SET QUERY_TAG = '<tag_here>';
There are some packages that can help do this for a DBT project, most notably the open source package dbt-snowflake-monitoring which sets tags for all models and tests and provides very intuitive and comprehensive cost models and monitors for all queries running on the warehouse.
❌ Fallacy 2: Performance of all query types scales linearly with larger virtual warehouses / compute
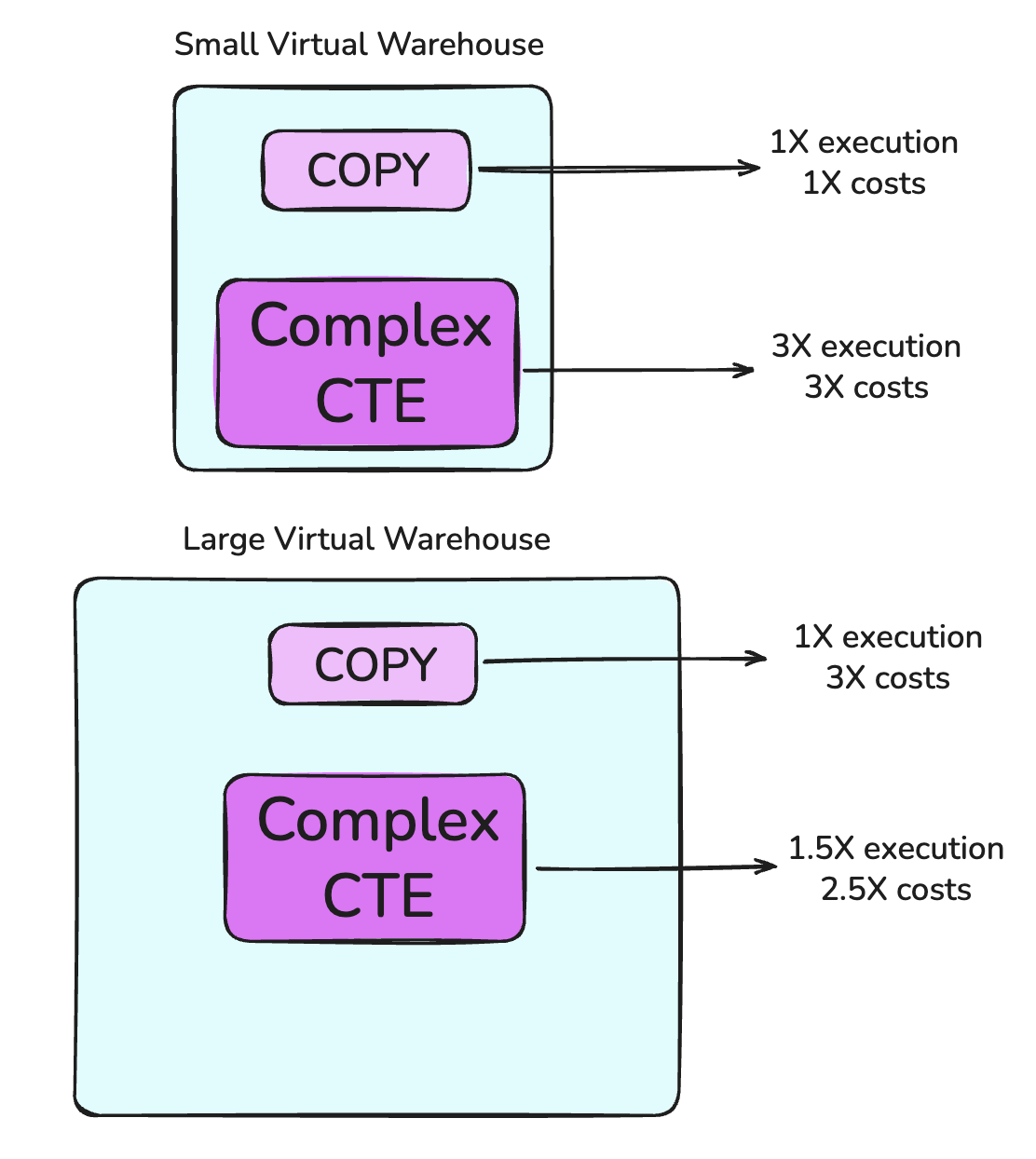
Consider two types of queries. One is a simple but frequent COPY statement which copies data from an external S3 stage into a snowflake table. Another query is a complex CTE with several complex joins creating a table. These two statements do not have the same performance implications.
A COPY statement is more strongly influenced by the amount of files and the size of the files we’re trying to copy over. This means that, with more compute, we might find a similar performance but we get a higher cost.
For the CTE, we might see that running a 2x more expensive warehouse cuts query time by 60%. If our query runs long enough, this means we safe more money in run time compared to what we are spending on increased compute.
❌ Fallacy 3: Using a single virtual warehouse to support different kinds of query loads is an efficient configuration.
As an extension from fallacy 2, many teams will have their use of a virtual warehouse evolve quite substantially over time but this is then not reflected in the composition of virtual warehouses and the queries they carry.
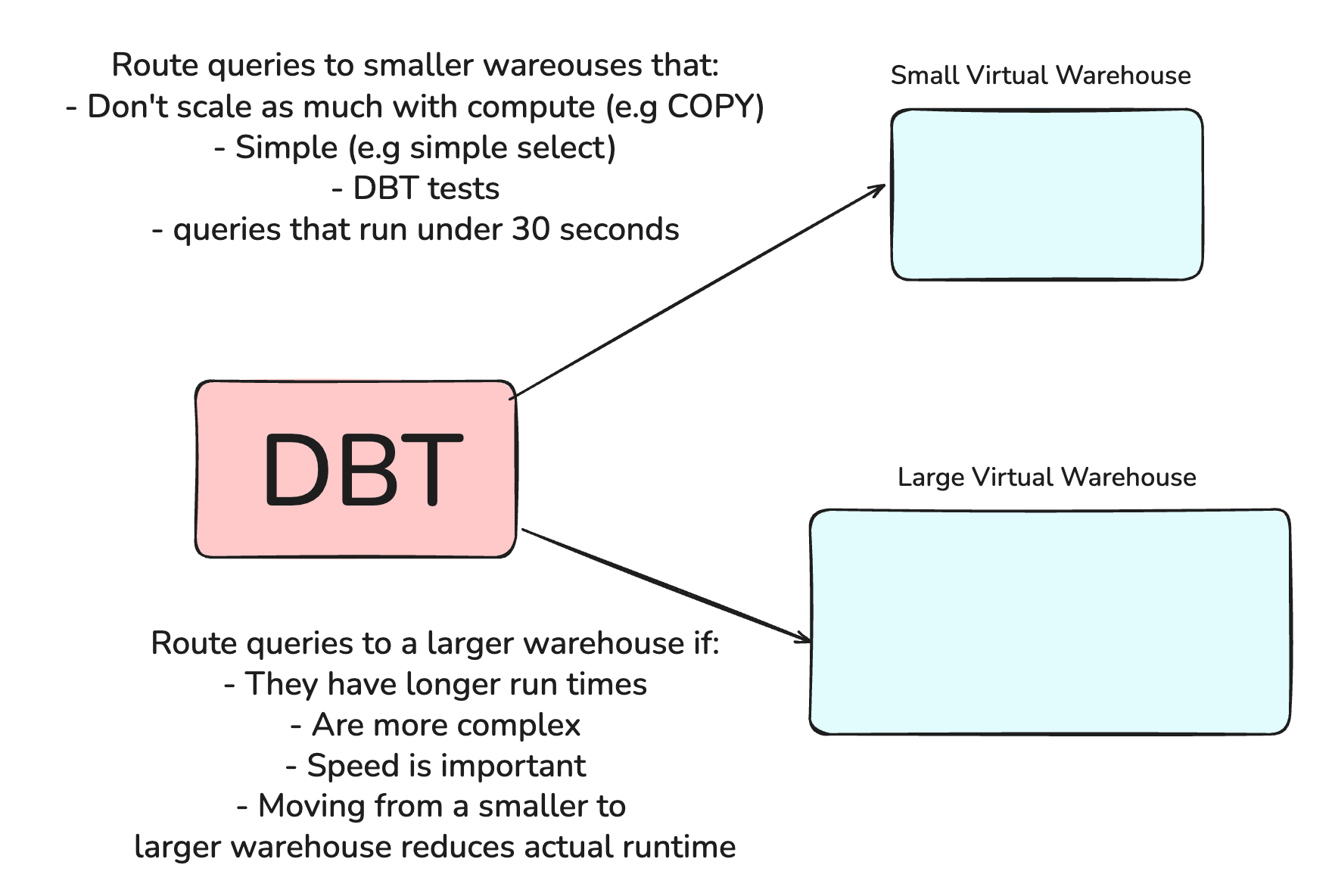
For data engineering oriented query loads such as COPY statements or INSERTS, DELETES and UPDATES in source tables, it is easy enough to separate these out into their own virtual warehouse.
For DBT projects, it’s also possible to set a different snowflake virtual warehouse in dbt on various levels such as the model level, the materialisation level, a mart level and many more.
If you have properly tagged queries, it is possible to analyse trends in query usage and set a virtual warehouse of the right size in a DAG oriented approach.
For example, for many dbt internal tests and commands such as source freshness, these queries might benefit from being run in a smaller warehouse.
Now you might counter: “but these queries have low run time so does this matter for total cost”? It does and it brings us to the next fallacy.
❌ Fallacy 4: Short running queries are not important for snowflake costs
This fallacy actually consists of a few sub-fallacies.
❌ Fallacy 4a: Virtual warehouses can handle any arbitrary amount of concurrency
While it is true that it’s possible to scale concurrency through the use of larger warehouses and using multi-cluster warehouses in enterprise accounts, this does not mean a virtual warehouse cannot choke on high query volume.
The default concurrency is 8 and goes up to 32 queries for a virtual warehouse cluster.
Now, consider the scenario where we are running thousands upon thousands of queries in a short span of time like what we might have if we’re running a DBT source freshness command.
Every transaction has a basic overhead to be executed. Running a high volume of small queries can cause higher than expected query waiting time and cost.
❌ Fallacy 4b: Small queries are handled consistently every time in every warehouse
I ran an experiment for a simple overwrite for slowly changing data for a set of tables between 1000 records and 50 million records in a snowflake XL warehouse with thousands of queries load and observed a peculiar pattern: The most expensive queries were not from the largest tables nor were they consistently expensive for the same query even though the data in and out remained the same.
The variation was staggering, the most expensive query of the same kind was in the single $ range and the least expensive was a 1000X cheaper.
While this may not sound like much, if you are replicating your tables 6 times a day and you have 500 tables where 1 query exceeds $1 you end up with a bill of $3000 a day for this replication.
Needless to say, moving this to a smaller warehouse resolved the cost of these queries tremendously, as we had less congestion on the older large warehouse and lower cost while running queries at a similar amount of time.
Fin
This concludes this weeks newsletter. Hope you picked up something new this week and if you did, show us your support by following the newsletter!