
Data Hustle #3: Knowledge Driven Development
Some musings on software 3.0

Let’s be honest.
When things started out with ChatGPT 3 years ago (It has only been three years ago?!), many people were pretending not to use it.
As things progressed, quite quickly, engineers would “leave it in the middle” whether they were using AI and how.
Now that we are seeing tooling for LLM-assisted code development gain popularity with copilot, cursor and windsurf, there’s no more dilly dallying around it:
Most all engineers are using AI in their workflows.
So, why do our code bases then not reflect this reality yet?
DISCLAIMER
I just want to preface this article with all the objections against an article like this:
This is NOT to say AI will overtake all software development.
This is NOT to say we should always be prompting for every software solution we write.
This does NOT mean we don’t have to put in time and effort into our designs and work on code iteratively WITHOUT AI.
This is to say that when we DO use AI, we should actually put in some work to use it as an effective tool for whatever we are doing.
Now that we got that out of the way, let’s get into it.
A new era of software engineering: Prompt Engineering?
Two weeks ago, Andrej Karpathy had some fascinating insights in his recent Y-combinator talk on how “software is changing again”.
In one part he was describing how the code base for self-driving evolved in tesla into roughly three paradigms:
Software 1.0 — Classical software.
Software 2.0 — The training and weighing of neural nets.
Software 3.0 — Prompts to the trained neural nets.
It has really struck me that the archetype of the codebase as a whole was changing and I think we can draw parallels into code bases as a whole in the industry in the years to come.
That got me to think however: what IS the best way to deal with Software 3.0 or prompts in a code base?
Everyone is talking to LLMs in isolation
Let’s take a step back and zoom out a bit.
Let’s say we have a code base for our team and we have 10 engineers that are prompting the LLM on the same code base to develop features for it.
How much time do you spend on refining your prompts and explaining your code base to an LLM?
Anyone who has put serious time into these will say: “A lot”.

Obviously, this improves with:
Every new iteration of AI models
Larger context windows
Smart tricks like code editors indexing your code base to understand it’s structure
— but that doesn’t mean that it will tackle the problem at hand in the most efficient way given current constraints.
In my own testing of this, I’ve seen this can go wrong in a couple of ways in practise. Some examples:
There are multiple legacy patterns in the code base that need to be ignored for certain pieces of code, but not for others.
The LLM (like a human) might try to take a shortcut and write a one-off solution that is not congruent with the pattern within the code base.
Having more irrelevant context decreases the amount of relevant context available for my query
Too much context can confuse models
The cost of this is quite significant.
If we know for a fact that engineers will be using LLMs for development
if we know that engineering hours are expensive
Then we need to acknowledge the fact that if we don’t optimize for their interactions with an LLM we are losing valuable resources in time and effort.
hours wasted prompting LLMs = Wasted Engineering hours = 💸💸💸

Do you really want all the engineers in a team reinventing the wheel every time when it comes to how they work with the LLM on more repetitive and predictable parts of a code base?
There has been some development in the field to fine-tune these sorts of issues.
Tools like cursor introduce the concept of rules which are reusable instructions that can be applied selectively based on user input, location of a file in a code base and more. Others like GitHub implemented organization wide knowledge bases that can be used by LLM coding agents in the IDE.
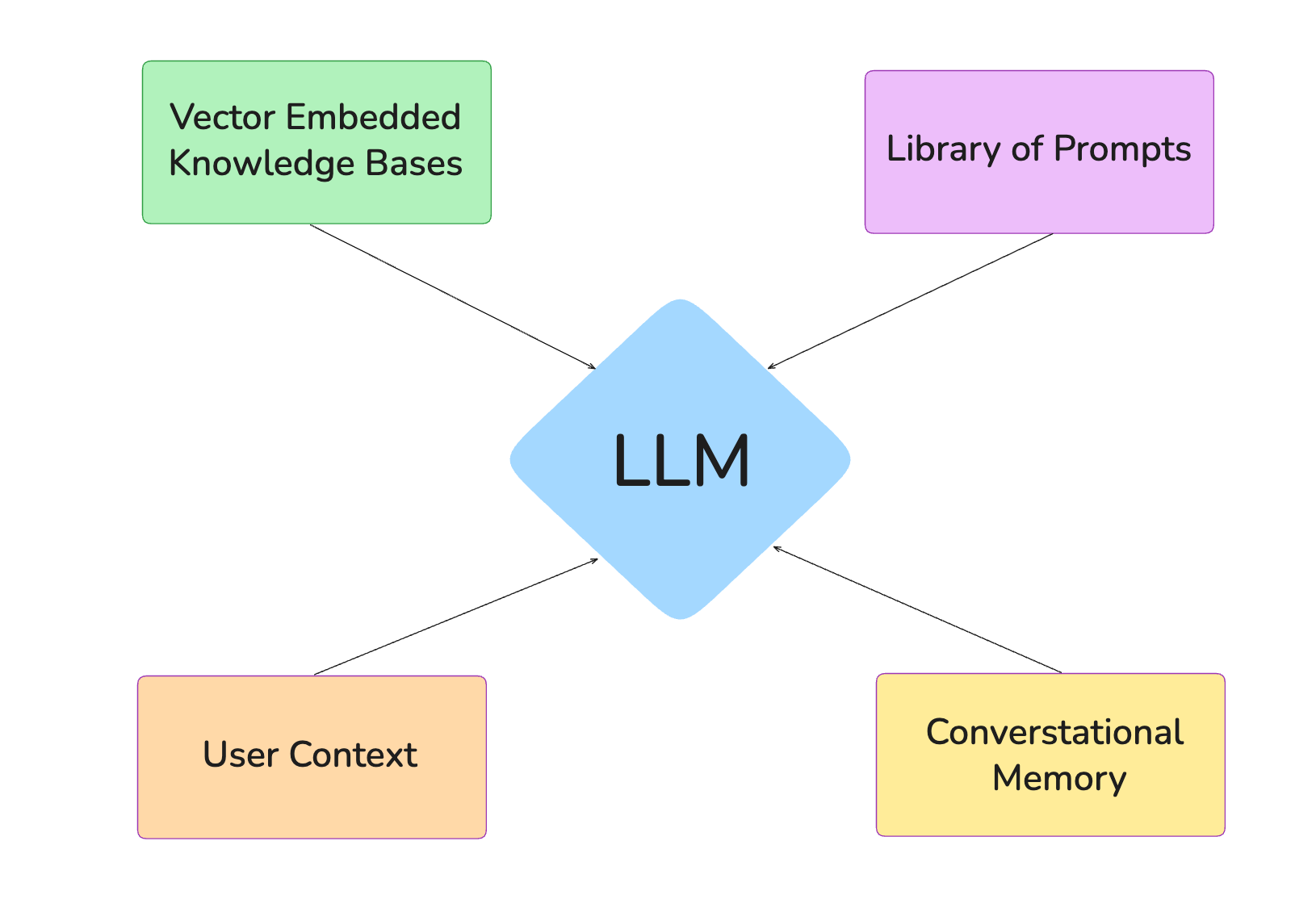
There is still work to be done on how knowledge and prompts will be organized in code bases — that is a given — but the concept of how to actually properly build and integrate this knowledge is a topic that will stay relevant no matter what technology will be deployed.
With that, there is a fundamental psychological change needed when it comes to developing and maintaining code as a team which I would like to coin as “knowledge driven development”.
Knowledge driven development is a development paradigm that prioritizes the structuring, curating and generation of context for AI and for humans in a code base.
For the purposes of this article, I will (mostly) not be going over knowledge basis but rather human crafted prompts and context.
Well then, let’s take a look at what that might look like in practise and the potential longer term ramifications of that.
Documentation re-envisioned: Prompt context as documentation
Once we reach a certain complexity in a code base, we all know that “just reading the code” to understand how everything ties together becomes increasingly complicated.
There is also the fact that as a code base grows in importance, the amount of engineers that will interact with it over time increases significantly.
As the amount of people interacting with the code base and each other grows, the maximum amount of social relationships and interactions grows quite aggresively:
Where C stands for the total connections in the social network and n the amount of nodes in the network.
Large code projects don’t just break on code complexity, they break on failures of communication at scale.
We all know documentation is always a significant challenge when it comes to maintaining a large code base. Not necessarily because it’s hard but because incentives are not aligned.
Why would you write documentation if that is not rewarded from an organizational perspective? How do you justify spending time on documentation that you could be spending on building new features for the business?

Now what happens if we define our documentation in a code base in the form of prompts / knowledge in our codebase.
Let’s say for theoretical purposes we have a simple modular code base. Let’s say we have a few system wide prompts that engineers can use, as well as prompts that are specific to the modules and stored within them.
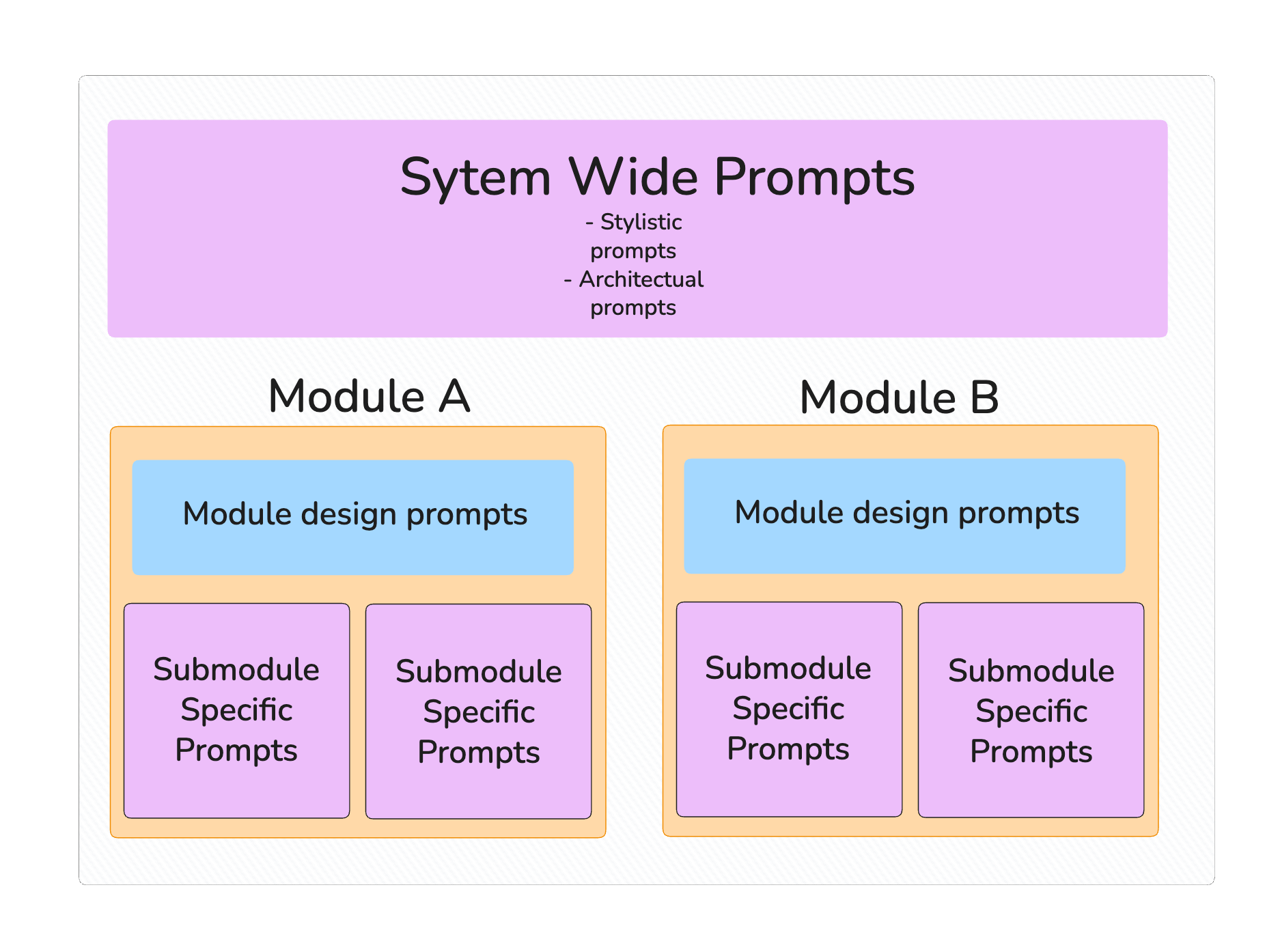
This does two things now.
A different engineer (perhaps a junior engineer) can read in plain english what the design and architecture of the codebase and modules is.
Engineers already familiar with the code base using LLMs for development can use these prompts when developing new features to get their LLM workflow to spit out the correct answer faster.
You see how documentation suddenly is more aligned with different incentives in the team?
We can now start to formalise in natural language what feature development in our code base ought to look like.
When I was a more junior engineer, I would learn a lot by observing the language used by more senior engineers. Whether it was:
a technology (e.g snowflake)
a development style (e.g test driven development)
a software design pattern (low-coupling)
an architecture (microservices)
Just being exposed to the language gave me the tools to ask better question to grow faster as an engineer. It gets engineers unfamiliar with the field much more quickly from an unkown unkown state to a known unknown state which is very powerful for learning.
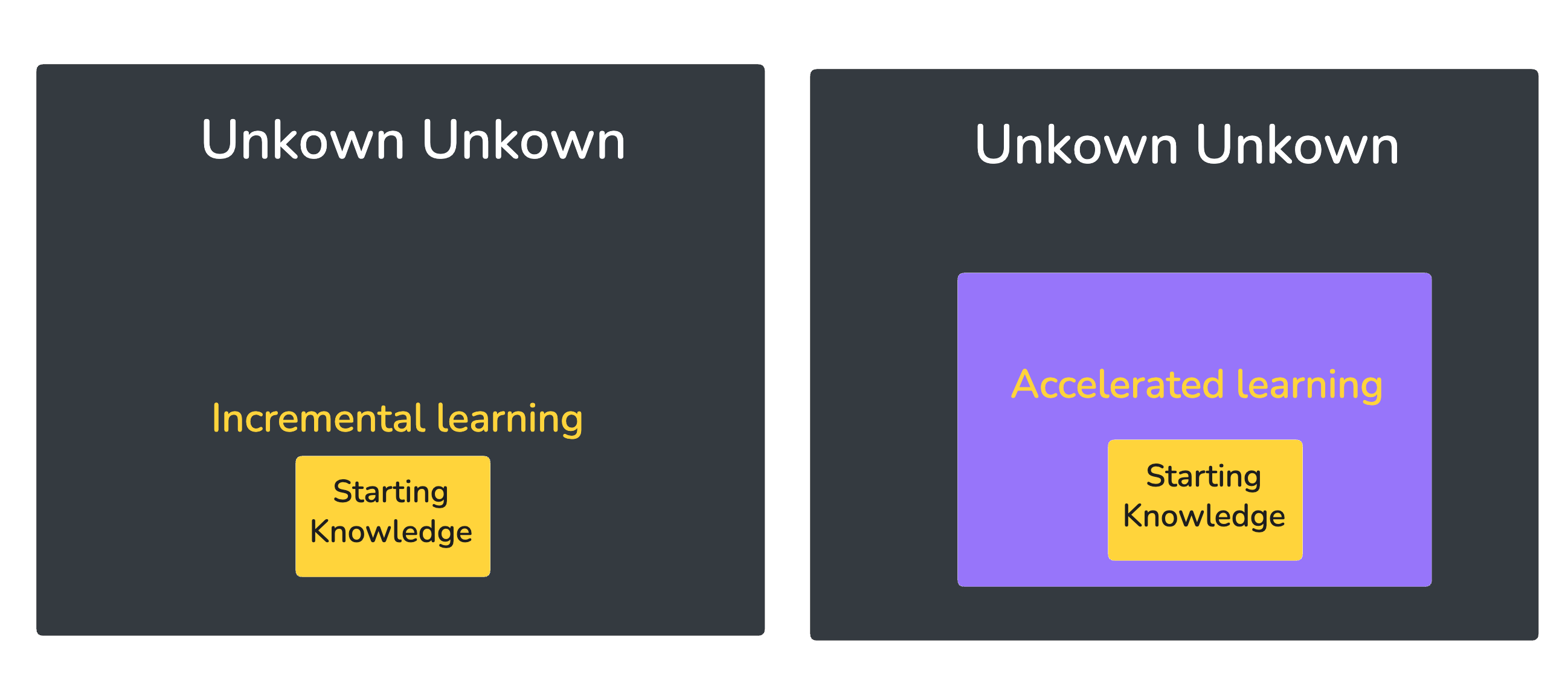
Encoding these principles in well written prompts in the code base allows me to guide junior engineers faster through the learning process — perhaps we can even use this context to help them start a conversation with the LLM. For example one could create a prompt
Explain to me what it means for the code base to have <x attribute> and show me example in the current code base highlighting these principles.
Alright sure but how do we get a nexus of prompts into our code base you may ask?
CI/CD and prompts and code reviews
If we acknowledge that context is vital in a code base, this has to change our perspective to how we do code review and deploy new code.
Similarly to how one would require the inclusion of tests in a code base when developing a new feature, we should require a Pull Request to include the addition or modification of context and changes in the code base.
The best way to encode such a practise in CI/CD is still debatable but it’s possible to start small.
Whenever you’ve developed a new feature for a code base, simply have the LLM summarize your conversation, the learnings and what-not into crystallized rules and context for future conversations and commit these to version control.
Whenever a new pattern is added to the code base or a new module is introduced, a requirement in scoping SHOULD include the context provided to LLMs and humans in the code base.
Another thing to consider about prompts is having LLMs as code reviewers of pull requests.
We are now seeing the emergence of LLM driven code reviewing tools either as SaaS products or as part of CI/CD pipelines within organizations.
Let’s take a step back.
What makes a code review a good code review anyway?
We will all have different answers and preferences that are strongly influenced by the code base, the team, the organization, the industry and a whole lot more.
If I work in a strongly regulated industry like healthcare for example, I might want to have more critical review when it comes to compliance in accordance to say HIPAA/HITECH.
What else makes a code review good?
Getting the perspective from different kinds of developers with different styles, preferences, and expertise tend to improve the quality of the review.
With this in mind, we could create developer personas out of prompts and rules and we can use these to scale and enhance reviews from different kinds of engineers.
If for example, we have a security team in an organization that is stretched thin but still wants to verify and question specific components of all the pull request coming into an organization, that team can write the context and prompts for their developer persona and we would be able to integrate this perspective automatically in an AI.

Still, it might be a lot of work to write context and prompts from scratch which is why it would be a good idea to consider other ways to generate these contexts as well.
Creating organizational knowledge out of documents
Most large software organizations will have tons of design documents, feature specifications and requirements lying around that were used to start developing features in their code base. Why don’t we use these as input to create appropriate context in a code repository?
There’s actually a wide plethora of context produced in an organization in meetings, notes, docs, you name it.
The question becomes: are you integrating and using this as effectively as possible?
It’s possible for example to process documents and create vector databases out of them storing the knowledge as embeddings.
These embeddings can be the basis of an simple AI agentic workflow that take these inputs from across the organization and produce valuable context and documentation that can be used and version controlled in a code repository for future work and reference.
Okay, we’ve talked a bunch about collecting input for prompts but how should we actually model them in our code base?
Prompt modeling
One of the questions on prompts would be how to model them at scale in a code base / organization. While there are no good answers or frameworks yet, some of the question that came up for me are:
What sort of prompt are we storing?
Is this a style guide?
Is this external context? (e.g docs, syntax)
Is this prompt part of the application?
Is this prompt part of the development flow?
Is this prompt meant for creative exploration?
Is this prompt meant for critical feedback?
What is the metadata we want to store around our prompt?
What model and settings did we use for this prompt?
How long or short should our prompt be? (Cursor for example suggest < 500 lines for a rule)
How “complex” is our prompt?
How “vague” is our prompt?
How do we label a prompt?
What overall structure do we maintain?
Do we have a flat structure of composable rules or do we allow hierarchy?
Do we store context in a central location, spread throughout the code base or do we have a separate repository altogether?
This is by no means an exhaustive list but in future posts and development in the field, it would definitely be interesting to think through the “meta” layer of this all.
Prisoners Dilemma in prompt sharing?
There’s an obvious catch to all of this prompt sharing. If a LLM-savvy engineer has a really effective personal system with highly effective customized prompts, custom context, etc, do they even want to be sharing their setup across an organization?
If one has a team with engineers that hold a zero-sum perspective that can create a classical prisoners dilemma
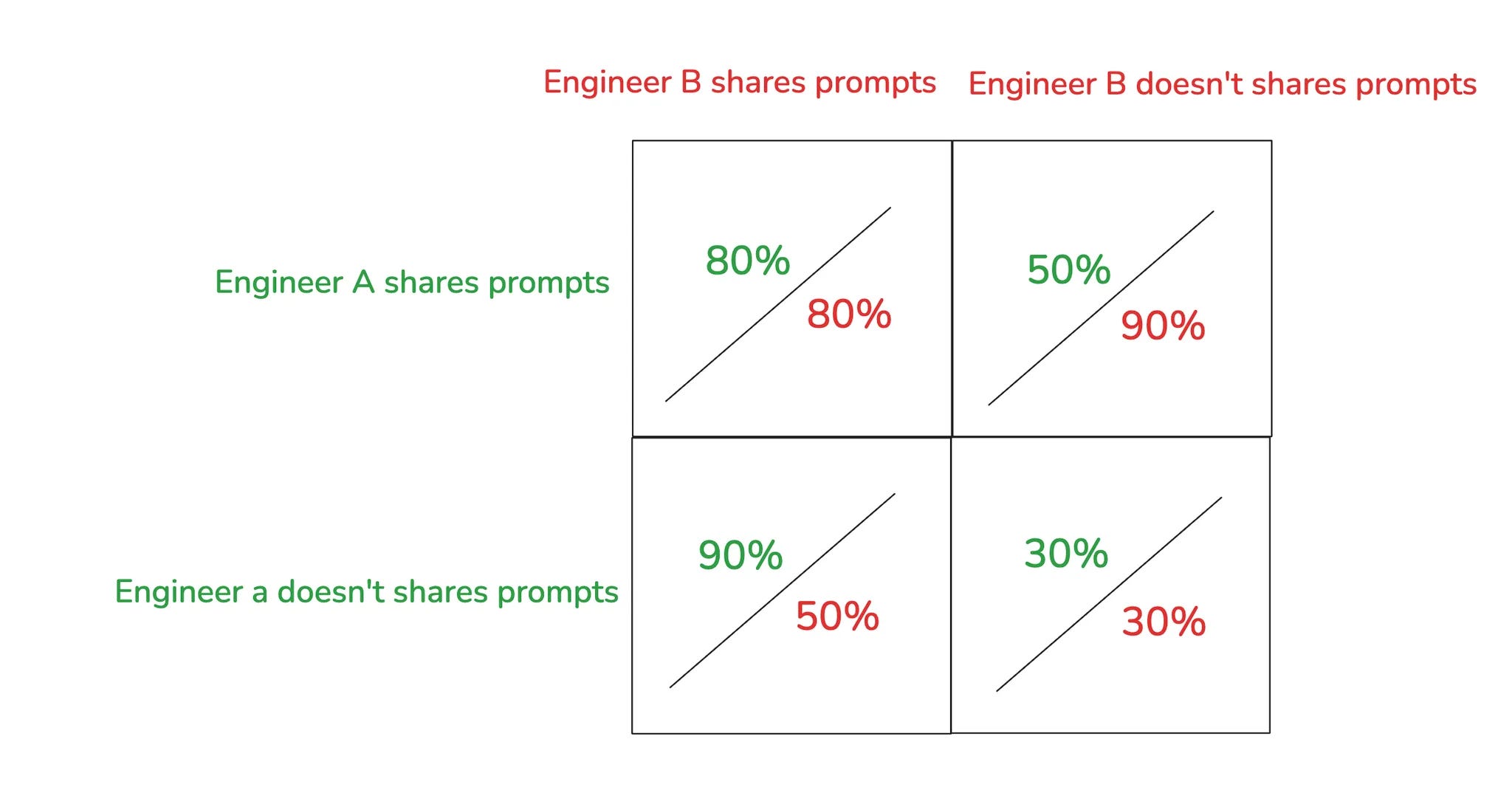
Let’s say we have an engineer A and B.
The organization decides to store and share prompts and context but both engineers have a personal choice as to how far they commit into this.
If we assume that both engineers have unique assets that can yield improved productivity and they do not talk honestly to each other, a funny situation arises.
If one engineer can have other engineers share all their knowledge but keep their unique assets to themselves, they could theoretically gain an asymmetrical advantage and create a wider margin in code output over other engineers output.
This changes drastically however if we measure ones impact on total output by the team.
In a more healthy team dynamic, what drives the impact of a senior+ engineer is not their individual output but their ability to lift and rise other engineers as a whole.
Making 10 other engineers 2x more productive makes you a 20X engineer, which is far better than being a 10X engineer all by yourself alone.
Now even if we have a healthy team dynamic, there is another big important question when it comes to sharing context: Who finally owns this all?
AI instructions: Fair use or intellectual property
If we consider prompt to actually be part of a code base what does this mean for the intellectual property in a a code base?
In software 1.0, intellectual property would be within the systems the organization as a whole has.
In software 2.0, the intellectual property might be the LLM and it’s weights (which is still a topic of much debate)
In software 3.0 however….english text is intellectual property of the organization?
Let’s try to extrapolate to a (possible) future where there is actually a ton of prompts and context defined for LLMs across code bases, either as part of the application or as part of the development experience.
Where do we draw the line of what is intellectual property of the organization and what is fair use outside of it?
If 20% of your code base is instructions for an AI, can’t we rule that it’s a crucial part of the application and therefore property of the firm?
Is the prompt valuable enough to even consider property or will this reduce in importance in future iterations of LLMs?
It’s a pretty funny twist in irony — AI tools scrape the internet and all of its intellectual property in it but then we claim intellectual property on it’s weights and the prompts.