
Data Hustle #2: Breaking Free from RBAC: Why Your Data Warehouse Needs Attribute-Based Access Control (ABAC)
The rise of the ABAC!

"Your data team just got a Slack message at 3 AM: 'Why can the intern see customer SSNs?' Welcome to the wonderful world of RBAC sprawl."
Anyone working with large Snowflake data warehouses eventually hits the same wall: Role-Based Access Control doesn't scale with modern data complexity.
What starts as a simple "give Sarah access to the customer table" spirals into creating role_customer_readonly_q4_marketing_manager_aggregate_unless_emergency_then_full_access

If this sounds familiar, you've crashed into the limitations every data team faces when managing thousands of dbt models across multiple environments.
This article dives into the practical reality of implementing Attribute-Based Access Control (ABAC) in a modern data warehouse - specifically Snowflake + dbt. I'll walk through the design principles you need to consider when developing a system like this. What will become apparent is that although the tooling exists, implementing this properly remains a complex effort in today's technical landscape.
Why RBAC Breaks Down at Scale
Let's look at what's actually happening in your data warehouse right now.
Classical RBAC works fine when you have 10 tables and 5 users. It breaks down spectacularly when you're managing thousands of views and tables across multiple data marts, dynamic DAG-based transformations, column and row-level permissions that change based on user context, and business requirements that shift faster than your deployment pipeline.

With traditional RBAC, every permission request flows through your data platform team.
❓Want access to the new customer churn model?
📥 Submit a ticket.
❓ Need to see revenue data but only for your region?
📥 Another ticket.
🙈 Your data team becomes a permission factory full of permission monkeys.
It's not uncommon for my clients to have 10-20% of their data tickets related to access requests in some way, shape, or form. As the number of models and end-users consuming data grows, the potential access permutations grow exponentially.
Modern data transformation tools make this even more painful.
dbt operates on DAG-based selectors - you can easily target "all models tagged with 'marketing'" or "everything downstream of dim_customers."
But try doing that with traditional roles? Good luck.
ABAC changes this entirely. Instead of pre-defining every possible role combination, you define attributes and let the system dynamically determine access patterns.
The scenarios where ABAC becomes essential include multi-tenant SaaS platforms where different customers see only their data with admin overrides, healthcare HIPAA compliance where access varies by role, department, and patient relationship, and financial services with regulatory requirements that change based on user location and data sensitivity.
Building ABAC on Snowflake
Let's look at what implementing this actually involves.
Dynamic Masking and Column-Level Security
Before diving into tag-based implementation, you need to understand when to use row access policies versus column masking policies - they serve different purposes. Row access policies control which rows a user can see entirely, while column masking policies transform the data within visible columns at query time. Think of row access as "can this user see this customer's record at all?" versus column masking as "this user can see the customer record, but only a masked version of their credit card number."
Tag-based masking combines Snowflake's object tagging and masking policy features, allowing a masking policy to be set on a tag using an ALTER TAG command. When the data type in the masking policy signature matches the column's data type, tagged columns are automatically protected. This eliminates the need to manually apply masking policies to every single column containing sensitive data.
Here's how this works in practice:
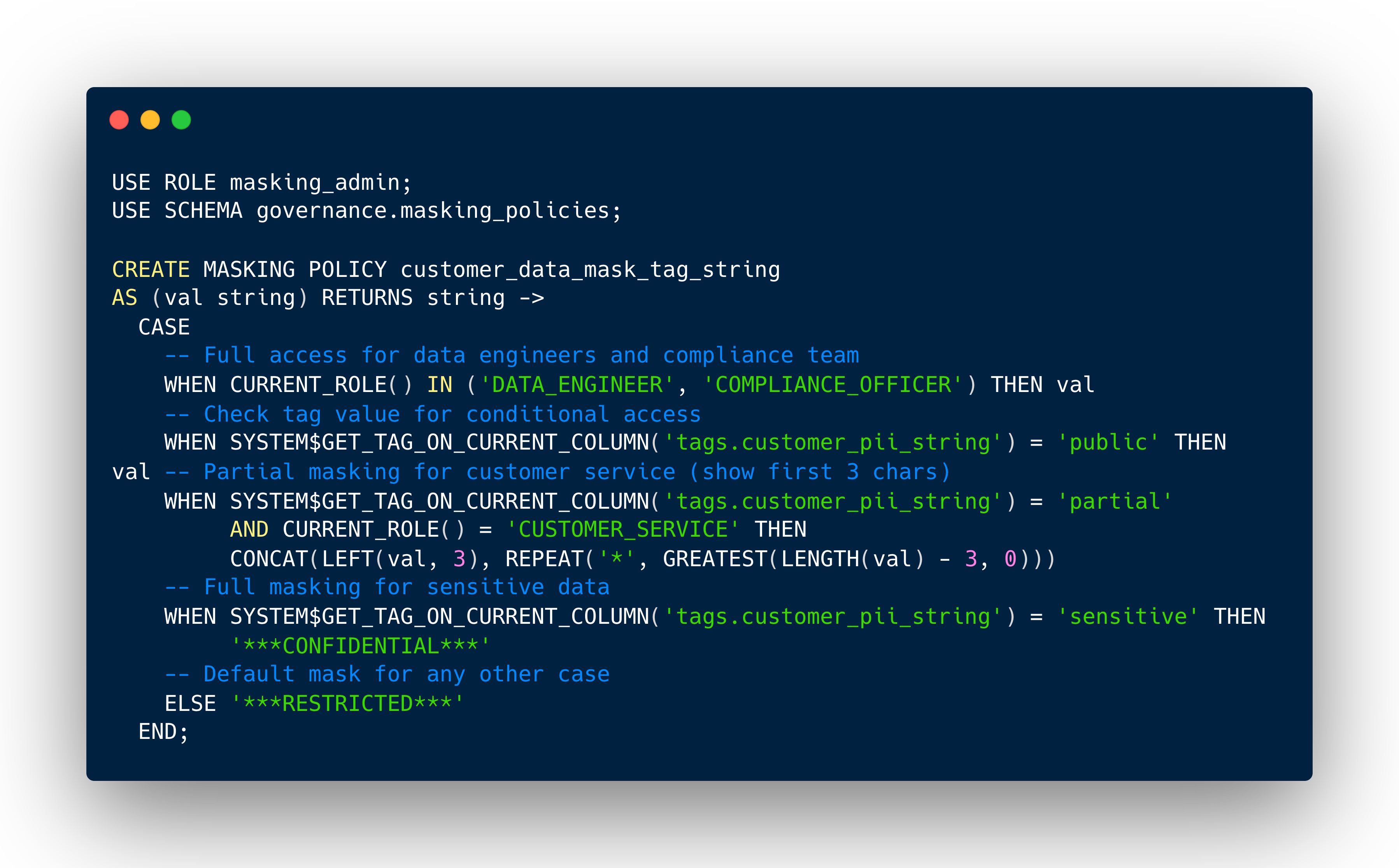
Tag-based policies allow administrators to write a policy once, assign it to a tag once, and have the policy apply to many objects automatically. No more manually tracking down every email column across hundreds of tables.
Managing Policies and Sub-Policies
Each tag can support one masking policy per data type - if a tag already has a masking policy for VARCHAR, you cannot assign another VARCHAR masking policy to the same tag.
This constraint forces you to think strategically about your tag architecture. You might need separate tags like pii_email_internal and pii_email_external rather than trying to handle all email masking with a single tag.
Most teams underestimate the complexity required for production-ready masking. "Mask or no mask" thinking will leave you with security gaps and broken test environments. You need granular masking strategies that consider both security requirements and operational needs.
Every single Snowflake data type needs a policy - VARCHAR, NUMBER, DATE, TIMESTAMP, VARIANT. Miss one, and you have a security gap.
The Attribute Data Model
This is where things get more abstract.
Your attribute model determines everything else.
Binary access (masked/unmasked) is just the starting point.
You need to consider things like:
Do we organize by business unit?
By functional role?
By data mart?
By data lineage?
Here's another thing most teams miss when implementing this in the BI layer: you need a dedicated role per user for the BI layer. Each user connects through their individual role, and each role must be defined within at least one group.
State Management Between dbt and Snowflake

You're managing two sources of truth: your dbt graph with tags and configurations, and the Snowflake production environment with actual applied policies. Treat dbt as your "plan" and Snowflake as the environment that must match. This infrastructure-as-code mindset prevents configuration drift.
Then there is a painful truth in dbt.
DBT is very permissible when it comes to yaml structures, a bit too permissible.
❗️What happens if a model is not defined in a yaml?
❗️What happens if all columns aren’t defined?
❗️What happens if data is removed?
❗️What happens if data types change?
and so forth.
Your team must build automations that fills in default tags based on model location, naming conventions, or lineage position.
If you're going to automate tag management, use ruamel.yaml - it preserves comments and formatting when modifying dbt model YAML files programmatically.
Then there’s process questions.
Who actually maintains these policies day-to-day?
Who determines whether a user should be part of the group?
How often are groups evaluated?
Most teams underestimate this operational overhead.
Some more practical things around applying tags
For complete masking coverage, you cannot deploy models directly to production. Use staging tables with policy application, then atomic swaps. Any gap between model deployment and policy application means unmasked data exposure.
While Snowflake metadata operations are free, they're not infinitely scalable and putting unnecessary query volume on a virtual warehouse can create unnecessary strain. Instead of running separate ALTER statements for each column like so:
ALTER TABLE customer_data ALTER COLUMN first_name SET TAG pii_data = 'sensitive';
ALTER TABLE customer_data ALTER COLUMN last_name SET TAG pii_data = 'sensitive';
ALTER TABLE customer_data ALTER COLUMN email SET TAG pii_data = 'sensitive';
ALTER TABLE customer_data ALTER COLUMN phone SET TAG pii_data = 'sensitive';Batch same-tag operations into a single transaction:
ALTER TABLE customer_data
ALTER COLUMN first_name SET TAG pii_data = 'sensitive',
ALTER COLUMN last_name SET TAG pii_data = 'sensitive',
ALTER COLUMN email SET TAG pii_data = 'sensitive',
ALTER COLUMN phone SET TAG pii_data = 'sensitive';Don't try to set multiple different tag types on the same column in one transaction - race conditions and inconsistent application await.
If you need to apply both pii_data and data_classification tags to the same column, do it in separate transactions to avoid conflicts.
Monitoring and Compliance
Snowflake's access history becomes your compliance lifeline. Y
ou need to track what data was accessed, in what format (masked/unmasked), by which user role, at what time, and for how long.
This isn't just nice-to-have monitoring - it's required for privacy compliance. When regulators ask "who accessed this patient data," you need answers, not shrugs.
You need real-time visibility into what's masked vs unmasked for each user, policy application success/failure rates, and unusual access patterns that might indicate policy violations.
This observability layer becomes critical for both security monitoring and compliance reporting.
Wrapping Up
Implementing ABAC isn't straightforward. If it were, everyone would be doing it already. You're trading the simplicity of "user has role X" for the complexity of "user with attributes A, B, C gets access level Y to data with attributes D, E, F."
But here's the thing - you're already dealing with that complexity. You're just managing it poorly with an explosion of specific roles and constant manual intervention. ABAC doesn't eliminate complexity; it organizes it in a way that scales.
Start small with clear use cases, invest in proper tooling and automation upfront, plan for the operational overhead of policy management, and build observability from day one.
Your future self (and your data governance team) will thank you when the next compliance audit rolls around and you can actually answer questions about who accessed what data, when, and why.

This concludes this week's deep dive into ABAC implementation.
Hope you picked up something useful for your own data governance challenges.
Got ABAC implementation questions or war stories? Hit reply - I read every email and love hearing about real-world data architecture challenges.
Need help implementing ABAC on your enterprise Snowflake + dbt setup? Consider our consulting services at
https://www.naronadata.com/ (formerly Zelytics).